項目応答理論の理論と実装
モチベーション: 変わった学校の定期テスト
ある学校では期末ごとに定期テストが開催されています。生徒は同じタイミングで同じ問題を解きます。この試験の結果から生徒の能力値を推定してほしいと依頼があったとしましょう。この場合すべての生徒は同じ問題を解いていますから、単純に問題の正解率を見たので十分でしょう。
ただ、この学校は大変に変な学校で、生徒ごとにランダムに違う問題が与えられているとするとしましょう。すると、正答率だけを見ているとたまたまかんたんな問題を与えられた生徒と、すごく優秀だけどめちゃくちゃ難しい問題ばかり与えられた生徒との区別ができませんから、おそらく不満が出てくるに違いないです。
このように、同じ問題を解いていない状態でも、解いている人の能力の比較をする枠組みの一つが項目応答理論と呼ばれるものです。
項目応答理論とは
項目応答理論は、複数のユーザがある問題を解いた結果 (正解 or 不正解) からそれぞれのユーザの能力や問題の難しさを推定する枠組みのことです。
身近な例だと TOEFL などが、この枠組をもとにユーザの得点を計算しています。
項目応答理論のモデリング
いくつかのバージョンがありますが、項目応答理論では、ユーザ $i$ の能力 $\theta_i$, 問題 $j$ の難しさ $\phi_j$, 識別度 $a_j$ としたとき, この問題をとけるかどうか?の確率 $q_{i,j}$ が以下の式で表されるとします。
$$ q_{i,j} = \sigma \left( D a_j (\theta_i - \phi_j) \right) $$
ここで $\sigma$ は以下で表されるシグモイド関数で、$D$はロジスティック関数を累積正規分布関数に近似するための定数です。
$$ \sigma (x) = \frac{1}{1 + e^{-x}} $$
シグモイド関数は入力の値が大きくなると 1 に, 小さくなると 0 に徐々に近づきます。すなわち問題が難しくなるとどんどんと解答できる確率がゼロになり、反対だと1に近づきます。反対にユーザの能力が大きくなると1に近づき、小さくなると0に近づきます。
識別度は問題が能力値に応じて解きやすくなる度合いを表します。例えば特定のレベルを超えたユーザはほぼ100%正答できるけれど、そうでないユーザはほぼ不正解になるような問題は、識別度が高いです。
最尤推定によるパラメータ推定
ユーザの正答確率がモデル化されたので、これを利用して今持っている正解・不正解のデータが得られる確率を計算しましょう。
今持っている回答結果が $N$ 個あり、そのうち $n$ 番目の解答が正しいかどうかを表す変数を $t_{n} \in \left\{0, 1\right\}$ としましょう。このとき、その結果の起こりやすさ(尤度) $p_n$ は
$$ p_n = \sigma (x_n)^{t_n} (1 - \sigma (x_n))^{1-t_n} $$
です。ここで、$x_n$ は$n$番目の問題のユーザを$i$, 問題を $j$ としたときに
$$ x_n = D a_j (\theta_i - \phi_j) $$
となります。これは、先程仮定したユーザが問題を解ける (正解する) 確率を、ベルヌーイ分布に適用したものです。
実際にはこれが$N$個ありますので、すべてを掛け算することで、回答結果データ $D$ 全体の尤度
$$ p (D | \phi, \theta, a) = \prod_{n=1}^N \sigma_n^{t_n} (1 - \sigma_n)^{1 - t_n} $$
となります。実際には数値安定の観点から対数をとったあと全体にマイナスをかけた、負の対数尤度 $f$ の最小化問題とします。
$$ \min_{\theta, \phi, a} f = - \sum_{n=1}^N \left\{ t_n \ln {\sigma(x_n)} + (1 - t_n) \ln({1 - \sigma(x_n)}) \right \} $$
この問題を解く方法はいくつかありますが、今回は勾配降下法 (勾配法) で解くことを考えます。勾配法では各ステップごとに目的関数のパラメータに対する微分を計算して、その方向へパラメータを更新します。今回最適化する対象となるのは $M$ 人のユーザごとの能力 $\theta_i (i = 1, 2, \cdots, M)$ と、$N$ 個の問題の難しさ $\phi_j$ と識別度 $a_j$ です。
はじめに、ユーザの能力に対する微分を考えて見ましょう。
$$ \begin{aligned} \frac{\partial f}{\partial \theta_i} &= - \sum_{n = 1}^N \frac{\partial f_n}{\partial x_n} \frac{\partial x_n}{\partial \theta_i} \\ &= - \sum_{n \in I} \left\{ t_n (1 - \sigma_n) - (1 - t_n) \sigma_n \right\} \cdot \frac{\partial}{\partial \theta_i} \left( D a_j (\theta_i - \phi_j) \right) \\ &= - \sum_{n \in I} (t_n - \sigma_n) D a_j \end{aligned} $$
ここで、ユーザー $i$ が回答している結果の集合を $I$ としました。
1行目から2行目で $\Sigma$ の対象が $N$ すべてから集合 $I$ になっているのは、ユーザ $i$ が関係しない結果に対して $\theta_i$ で微分するとゼロになるためです。またシグモイド関数に関する微分で成り立つ $\sigma' = \sigma (1 - \sigma) $ を利用していることに注意してください。
問題の難しさ、識別度についてもほとんどこれと同様に計算ができます。ここで、問題 $j$ に対する解答の集合を $J$ としました。
$$ \frac{\partial f}{\partial \phi_j} = - \sum_{n \in J} - (t_n - \sigma_n) D a_j $$
$$ \frac{\partial f}{\partial a_j} = - \sum_{n \in J} - (t_n - \sigma_n) D (\theta_i - \phi_j) $$
実際に推定してみる
コードは以下の gist を参照ください。
サンプルデータの作成
実際に推定をおこなうために、人工的に問題への回答結果のデータを作成します。
作成方法は以下のとおりです。
- まずユーザがもつ能力と問題の難しさと識別度の正しい値をランダムに生成します。
- 次にランダムにユーザ・問題を取り出して、正しい値をもとに反応応答理論で計算される確率 $p$ を計算し、
- 確率 $p$ で正解, $1-p$ の確率で不正解とするベルヌーイ分布をもとにして、解答が正解したかどうかを作成します。
ユーザの能力と問題の難しさは正規分布から、識別度は 0.5 ~ 2 の間の一様分布としました。問題の数は 100個, ユーザ数は 1000人 で回答結果の組み合わせは 1万件とします。
N_PROB = 100 N_USER = 1000 true_user_levels = np.random.normal(0, 1, size=N_USER) true_prob_levels = np.random.normal(0, 1, size=N_PROB) true_problem_disc = np.random.uniform(0.5, 2, size=N_PROB) results = [] for _ in range(10000): i, j = np.random.randint(0, N_USER), np.random.randint(0, N_PROB) p = calculate_correct_answer_probability(theta=true_user_levels[i], phi=true_prob_levels[j], a=true_problem_disc[j]) t = np.random.binomial(n=1, p=p) results.append([ i, j, t ]) results = np.array(results) df = pd.DataFrame(results, columns=["user", "problem", "answer"])
最急降下法による推定
はじめに勾配法によってパラメータを推定します。
# 問題の難しさ problem_levels = np.zeros(shape=N_PROB) # 問題の識別度 problem_disc = np.ones(shape=N_PROB) # ユーザの問題を解く能力 user_levels = np.zeros(shape=N_USER) D = 1.71 for step in range(10): _user_levels = df["user"].map(user_levels.__getitem__) _prob_levels = df["problem"].map(problem_levels.__getitem__) _prob_disc = df["problem"].map(problem_disc.__getitem__) sigma = calculate_correct_answer_probability(_user_levels, _prob_levels, _prob_disc) # 数値安定性のため極端な確率にならないよう min / max をきめて clip sigma = np.clip(sigma.values, a_min=1e-8, a_max=1 - 1e-8) diff = - df["answer"] + sigma print(objective(df["answer"].values, sigma=sigma)) # 問題の難易度の勾配 partial_prob_levels = diff * -1 * D * _prob_disc # ユーザの能力の勾配 partial_user_levels = diff * D * _prob_disc # 問題の識別度の勾配 partial_prob_disc = diff * D * (_user_levels - _prob_levels) # パラメータの更新 user_levels -= partial_user_levels.groupby(df["user"]).mean().values - 1e-8 * user_levels problem_levels -= partial_prob_levels.groupby(df["problem"]).mean().values - 1e-8 * problem_levels problem_disc -= partial_prob_disc.groupby(df["problem"]).mean().values
結果の可視化
正解・不正解の問題に対する期待正答確率の分布は以下の通りになりました。正解のとき確率1に近く、不正解のとき0に近いようにパラメータ更新ができていることがわかります。
次に問題・ユーザの真の能力と推定された能力を見てみます。
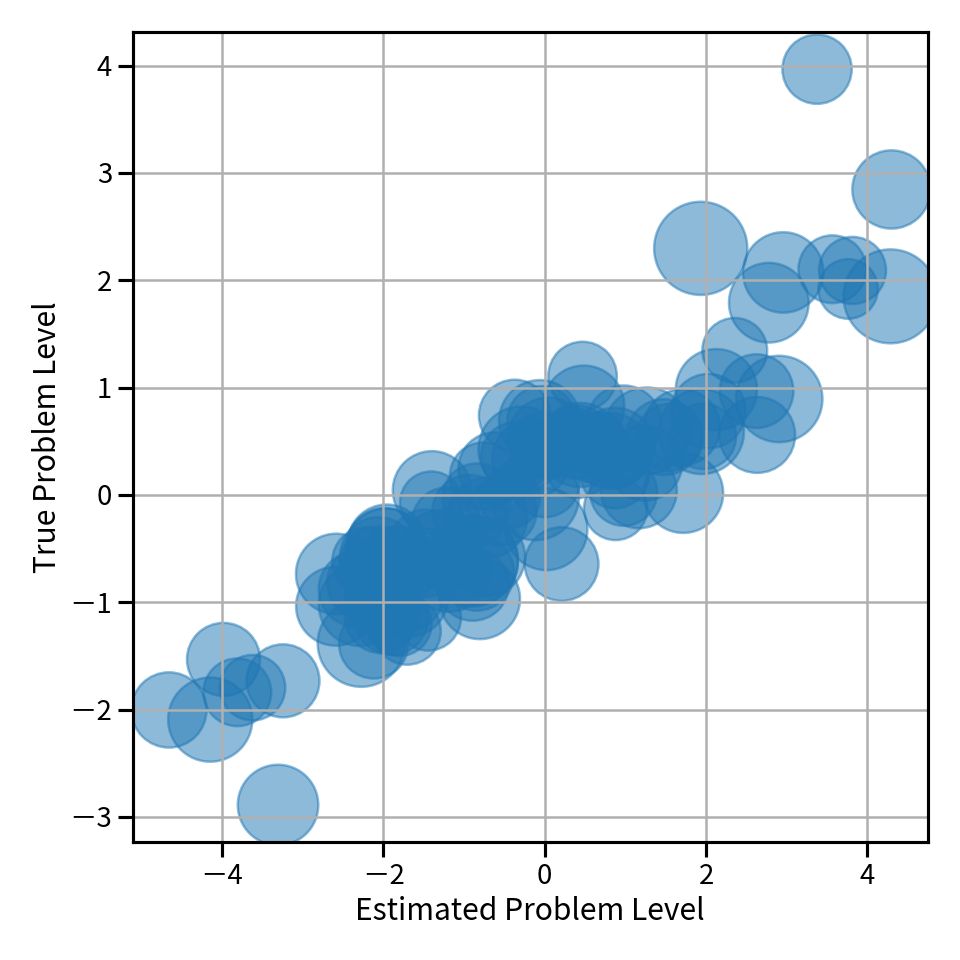
横軸に推定された問題の難しさ、縦軸に正しい問題の難しさを scatter plot として可視化したものが以下の図です。これを見ると対角線に並んでいて、概ね良い推定値が得られていることがわかります。

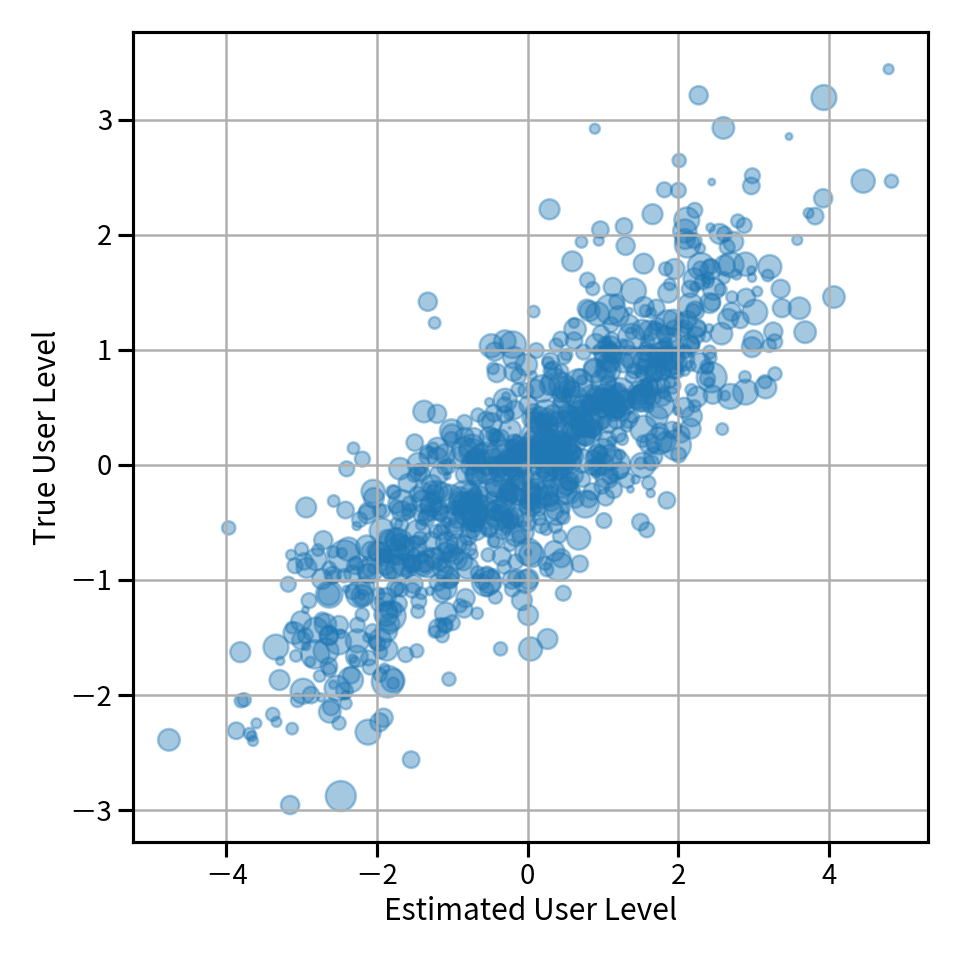
同様にユーザの能力に対しても plot したものが以下の図です。ズレはあるもののこちらも概ねよく推定できていることがわかります。

逐次的にデータが来る: Online Optimization の場合
先程の勾配降下法では、全体のデータを持っている前提で勾配を計算していました。実際の問題では、データが逐次的にやってくるような場合もあります。例えばオンライン英単語学習サイトがあって、ユーザが回答するたびにユーザの能力や問題 (この場合だと単語の難しさ) を更新したい、という場合などです。
このように逐次的にデータが来ることを前提とした最適化問題は Online Optimization と呼ばれます。これを解く方法の一つは、今やって来たデータだけで勾配を計算してパラメータを更新するというやり方です。これは、確率的勾配降下法とやっていることがほぼ同じですが、確率的勾配降下法ではデータセット全体はすでにあると仮定している一方 online optimization ではデータセット全体は手元にないと仮定している点が異なります。また online な設定ではデータは基本的に一回しか使わないですが、確率的勾配降下法では何度も繰り返してデータセットを利用して最適化を行います。
今回は回答結果データは1件づつやってくるとして、その結果についての勾配を使ってパラメータを更新します。
先程の実装と違い df.iterrows() でデータを1件づつ取得して、その勾配を計算している点が異なります。
from tqdm import tqdm # 問題の難しさ problem_levels = np.zeros(shape=N_PROB) # 問題の識別度 problem_disc = np.ones(shape=N_PROB) # ユーザの問題を解く能力 user_levels = np.zeros(shape=N_USER) D = 1.71 snapshots = [] for i, row in tqdm(df.iterrows()): _user_levels = user_levels[row["user"]] _prob_levels = problem_levels[row["problem"]] _prob_disc = problem_disc[row["problem"]] sigma = calculate_correct_answer_probability( theta=_user_levels, phi=_prob_levels, a=_prob_disc ) sigma = np.clip(sigma, a_min=1e-8, a_max=1 - 1e-8) diff = sigma - row["answer"] # 問題の難易度 partial_prob_levels = diff * -1 * D * _prob_disc # ユーザの能力 partial_user_levels = diff * D * _prob_disc # 問題の識別度 partial_prob_disc = diff * D * (_user_levels - _prob_levels) user_levels[row["user"]] -= partial_user_levels - 1e-4 * _user_levels problem_levels[row["problem"]] -= partial_prob_levels - 1e-4 * _prob_levels problem_disc[row["problem"]] -= partial_prob_disc * 1e-2 + 1e-6 * (1 - _prob_disc) if i % 100 == 0: snapshots.append([ user_levels.copy(), problem_levels.copy() ])
結果の可視化
さきほどの最急降下法と同じように問題・ユーザの推定結果と正しい値を plot したものが以下の図です。オンラインの設定でも、ある程度の推定ができていることがわかります。
ユーザの能力推定値の推移
ユーザの推定能力値は時系列に伴って逐次更新されます。実用上はステップ数が増えると正しい推定値を得てほしいですよね?
ステップごとの変遷を見るため、online の更新 100 回ごとに各々のユーザの推定能力値を可視化したものが以下の図です。
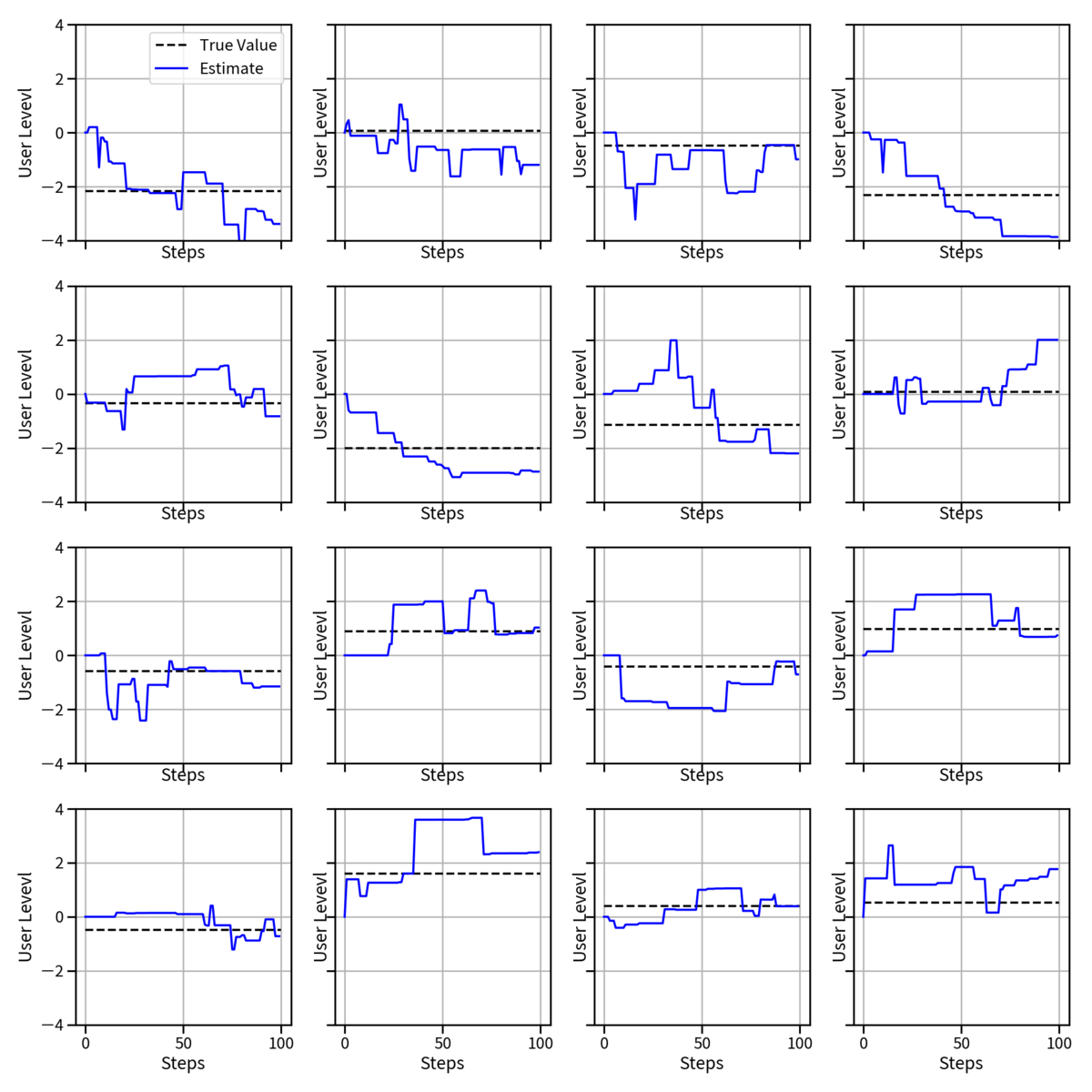
黒い点線がそのユーザの真の能力で、青い線がステップごとの推定値の遷移です。これを見ると大体の値は推定できていますがたまに大きくハズレた推定をしてしまっているものがあることがわかります。これは online 更新だと今までの回答履歴等を考慮していないため、ある難しい問題にたまたま正解したりすると急に値が増えたり逆に減ったりする可能性があるためです。
同じように問題ごとの推定値変遷を可視化すると以下のようになります。ユーザよりも問題のほうが数が少なくて、一つの問題あたりの回答数が多いため、ユーザの推定値よりも正確性が高そうであることが伺えます。

今回の問題設定の課題
今回のモデリングではユーザの能力が時系列に対してかわらないことを仮定しています。実際には時間がたつとユーザの能力や問題の難易度も場合よっては変動しますので、それらを組み込んだモデルを使う必要があります。 (今日はいったんここまで。気が向いたらまた調べる。)