Kaggleで勝つデータ分析の技術: 今までの機械学習本と全く違う最強の実務本
この度光栄なことに著者の @Maxwell さんから「Kaggleで勝つデータ分析の技術」 を献本いただきました。 私事ですがこのような形で献本頂いたのは初めての経験だったのでとてもうれしくまた恐縮している次第です。

光栄なことに @Maxwell_110 さんからKaggleで勝つデータ分析の技術を頂きました〜 目次の充実が話題になってましたがサラッと見ただけでも濃い内容満載で読むのワクワクです😆 https://t.co/VTKmsR5Z6s pic.twitter.com/yuRS72YyTs
— ニューヨーカーGOTO (@nyker_goto) October 2, 2019
「せっかく本を頂いたので書評をかこう!!」と思ってここ数日読み進めていたのですが、この本が自分がここ一年ぐらいで読んだ機械学習に関連する本の中でもずば抜けて内容が濃くまた情報量の多い本であったため「これは僕も頑張らねばならぬ…」とウンウン唸っているうちに今まで時間が経ってしまいました。
すでに全体像に関する書評に関しては u++さんの記事や ばんくしさんが書かれた素晴らしい記事ありますのでそちらを参考にしていただければと思います。
お二方とも超がつく高評価でこの本の完成度が伺えると思います。
お二人と同じようなことを書いても差別化ができない(?) ので以下では nyker_goto 的な視点 (実務でデータ分析をしていてシステムへの組み込みなども自分でやっている人) でこの本を見ていきたいと思います。
体系的に Kaggle の知がまとまっている最強のほん
「Kaggleで勝つデータ分析の技術」と銘打っている通り、Kaggle のノウハウがこれまでかというまでに詰まっています。
まず Kaggle への参加方法までを丁寧に説明するところから始まり、評価指標の話や、過去のソリューションの解説、特徴量の作り方や XGBoost などの Kaggle でおなじみのアルゴリズムの説明、はたまたチューニングノウハウまでもがまとめてあります。*1
上記内容は体系だった本があるわけではなく、Kaggle の DiscussionやNotebook、Kagglerのブログなどに散らばっている内容です。これらを一気に一つの本で読むことができるというのは個人的にとんでもないことだと思っています(自分が Kaggle 始める前に読みたかったです)。これだけでも本の値段にお釣りが来る価値があると思います。
これから Kaggle を始めたいと思っている人はこの本をベースに知らないことを調べながら学習していけば良いと思いますし、また Kaggle をやっている人もこの本を見て復習したり、抜けている知識や議論の分かれる問題に対して意見を考えるのも非常にためになると思います。
Validation の作り方の専門書
そして個人的にこの本の一番の勝ちは Validation の作り方のセクションにあると思っています。 なぜなら Validation をちゃんと作るというのは Kaggle だけでなく 実務で機械学習を使う上で一番大事なのにも関わらず、他の本ではほとんど触れられてこなかった と思っているからです。
Trust CV
Kaggle では Trust CV とよく言われます。Trust CV とは簡単に言うと、今の見えているランキングの値を信じるのではなく、自分の学習データで評価した自分のモデルの評価値を信じなさい、ということです。これはランキングばかりを追いかけているとランキングに過学習してしまい最終的な評価値が悪化してしまうことを避けるための格言です。
この Trust CV を最もしなくてはいけないのはいつなのか、というと実は実務で機械学習のモデルを作るときなのではないか、と僕は思っています。
ex). 時系列のデータの予測モデルを作るとき…
例えば時系列の予測を行うモデルを作りたいというとき CV の切り方がわかっていない人は単純に KFold で Fold ごとの validation score がモデルの評価値だと思い、学習を行うでしょう。(なんなら KFold している時点でまだまし、なのかもしれません。) そうして Production にいざデプロイすると全然スコアが出ない、なんていうことはざらにあるんだろうと思います。これは Production では常に未来の予測をしているのに対して単純な KFold だと未来の情報も使って予測ができるようになっていてモデルが予測する際の条件が揃っていないことが原因と考えられます。
上記のミスは一般的な? Kaggler なら当たり前にわかることなのですが、なんかちょっと前に京都大学の先生がこれをやっていたり、専門家でもやってしまいがちなミスです。 じゃあなぜそんなミスが専門家でもやってしまいがちなのか、というと一般的な機械学習のアルゴリズムの本にはそんなことは「一切」載っていないし重要視されていないからなんだろうと思います。
一般的な機械学習の本が全然触れないデータ分析のこと
それは僕が大好きなPRMLでもカステラ本でもみどりぼんでもそうです。 それらの本で対象にしているのはモデルの仕組みであって、実問題を解くためにTestデータとTrainデータをどのように用意すればいいかは範囲外だからです。そして厄介なことに scikit-learn とかで得られるデータってだいたい KFold で十分なんですよね… mnist しかりあやめしかり。
実データはそんな単純な問題ではないことが多いですし、大抵は時系列やユーザーごとに切り分けて考えることが必要です。 それって実際に問題を解く際には避けては通れない道なのですよね。(ここに機械学習の勉強と、実問題を解くことができるの一つの壁があると思っています。)
一方で Kaggle はシビアにそれがわかります。だって「それでは勝てない」のです。勝てないがゆえに勝てるためにちゃんとCVをして自分のモデルの能力をしっかりと計測するという文化が出来上がってきています。
そして、このしっかりモデルの力を測る力は、実務でモデルを適用しようとしている人が一番必要な力です。だってちゃんとモデルを測れなかったら Production で痛い目を見るからです。本番での性能なんて知ったこっちゃない、っていう人は別かもですが…
まとめ
以上ながなが書きましたが、この本は
- Kaggle をやりはじめる人にとって案内となる本であり
- 同時に Kaggle 経験者も知識の振り返りに使える本であり
- 実は Kaggle をしない実務で機械学習をしている人が一番必要としている本
だと思っています。要するに 機械学習する人はみんな必要 です。とにかく素晴らしいので、ぜひ皆さん手にとってご覧になってください。
最後にこのような素晴らしい本を書いてくださった著者のみなさまに感謝を述べてこの書評を終わりとさせてください。
ここまで読んでいただいてありがとうございました。
*1:僕もチューニングの気持ちを書いたエントリがありますが完全にリプレイスされました
elasticsearch で cosine類似度検索する
全文検索エンジンで cosine 類似度検索できるらしいというのを bert × elasticsearch の記事で見かけてとてもたのしそうだったので、自分でも環境作るところからやってみました。
やっているのは以下の内容です
- docker/docker-compose で elasticsearch x kibana x jupyter の立ち上げ
- jupyter の python から実際に特徴量ベクトルの登録 + 検索の実行
- kibana での可視化 (ちょっとだけ)
紹介するコードはすべて以下のリポジトリから参照できます。
Requirements
- docker
- docker-compose
Setup
docker-compose build docker-compose up -d
以上実行するとサーバーが3つ立ち上がります。docker-compose ps をやって以下のような感じになってれば成功です。
23:00:17 in start-elastic-search on master on 🐳 v18.06.1 took 24s
➜ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------------------------------
startelasticsearch_elasticsearch_1 /usr/local/bin/docker-entr ... Up 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp
startelasticsearch_jupyter_1 /usr/bin/tini -- jupyter n ... Up 0.0.0.0:8888->8888/tcp
startelasticsearch_kibana_1 /usr/local/bin/dumb-init - ... Up 0.0.0.0:5601->5601/tcp
elasticsearch
今回の主題である elasticsearch は localhost:9300 でつながります。これを直接 REST API で叩いても当然つかうことが出来ます。
定義ファイルは ./elasticsearch ディレクトリに入っています。
詳しくは elasticsearch 公式 docker document を参考にして下さい
https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
Production Usage の時の注意点 https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#_notes_for_production_use_and_defaults とかもあります。
Kibana
Kibana は elasticsearch 用のクライアントアプリケーションです。 localhost:5601 で kibana container とつながっています。開いて適当なサンプルデータを突っ込むとわかりますがとにかくめっちゃいろんなことができることはわかります。開いて色々動かすだけでもわりと楽しいです。
設定について
kibana の container はデフォルトで elasticsearch:9300 につなごうとするので elasticsearch も default の 9300 で起動するよう特に何もいじっていません。
設定ファイルを弄りたい場合には environment に記述する若しくは kibana.yml を bind して up すると良いです。詳しくは kibana の docker document を参考にして下さい。
http://localhost:5601 にアクセスすると kibana server にアクセスできます。
jupyter
python から elasticsearch 使いたいよね、ということで jupyter notebook server を用意しています。
jupyter には http://localhost:8888/tree/notebooks からアクセスできます。 password は "dolphin" です。
python 環境には elasticsearch が pip で入っていますので python client はデフォルトで使うことが出来ます。
Sample notebook
いくつかサンプルのコードが入っていますので参考にして下さい。
特徴ベクトルでの類似度検索
~/client/notebooks/sample_search_by_cosine-sim.ipynb に特徴ベクトルでの類似度検索を行うサンプルが入っています。
128 次元のベクトルを "matching" index に 100000 件登録して、クエリのベクトルとコサイン類似度の意味で近い順にソートする、ということを行っています。
例えば以下のような例が応用でしょうか。
- 画像の特徴ベクトルでの類似度検索
(クエリ画像と、マスタ画像の類似度を arcface や center-loss などの metric learning で得たモデルの特徴量でソート) - 文章を表す特徴量でのソート
(SWEM など文章を埋め込む(embedding)手法)
Result
検索の時間は以下のようになりました。 elasticsearch 爆足だぜ :D
| method | %%timeit |
|---|---|
| scipy.spatial.distance & list内包記法 | 3.27 s ± 17.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) |
| scipy.spatial.distance & joblib parallel | 5.2 s ± 108 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) |
| elasticsearch | 43.7 ms ± 661 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) |
Kibana でも見る
上記の notebook を実行すると実際に index が出来上がるので, Kibana からもデータを見ることが出来ます。
インタラクティブに見る
http://localhost:5601/app/kibana#/management/kibana/index_pattern?_g=() にアクセスすると index の pattern をいれる画面が立ち上がります。ここに作成した "matching" と入力して Next Step > create index patterns と進みましょう。

その後左側のナビゲーションの上から二番目、方位磁石っぽいアイコンを押します。するとずらずらっとデータが 100001 件出てきます。これが今 elasticsearch に "matching" index として登録されているドキュメントです。

この画面もまあまあできることが多いのですが一番わかり易い使い方はうえの search toolbar だと思います。ここにカーソルを当てるといい感じにクエリをサジェストしてくれます。なかなか楽しいです。

また http://localhost:5601/app/kibana#/dev_tools/console?_g=() からクエリを叩くことも出来ます。たとえば
GET matching/_search { "query": { "match_all": {} } }
とかやると全件取得が出来ます。楽しいですね。

参考
連続変数で StratifiedKFold
pandas.qcut で int に変換すると良さげ
from sklearn.model_selection import StratifiedKFold import pandas as pd def get_stratified_fold_split(X, y, n_folds=10, q=20): # Categorical.codes で各クラスに対応する int が取得できる y_cat = pd.qcut(y, q=q).codes fold = StratifiedKFold(n_splits=n_folds, random_state=71) return fold.split(X, y_cat)
q は int 化するときの分割数なので n_folds に合わせていい感じに合わせると良いかな?
RAdam: Adam の学習係数の分散を考えたOptimizerの論文紹介
表題の通り噂の最適化手法 RAdam の論文 On the Variance of the Adaptive Learning Rate and Beyond を読んだので, そのまとめです!!
概要
一言でいうと「今までヒューリスティックに行っていた Adam 学習開始時の LR 調整を自動化できるような枠組みをつくったよ」ということになると思います.
考える問題
この論文で, 考えていくのは機械学習のように多数のデータから成る目的関数を最小化するような問題です. 特にニューラルネットワークの学習では勾配法, 特に SGD (確率的勾配降下法) と呼ばれる方法を用いることが一般的です.
SGD には様々な adaptive バリエーションがあります.この adaptive とは問題の特性を生かして, SGD を早くするような工夫を指しています.
一般的な形式
一般的な adaptive と呼ばれる SGD は, 方向を決める $\phi$ とそれを補正する係数である $\psi$ を用いて記述することができます.
例えば adam の場合は勾配には勾配の指数加重平均を, 補正係数には勾配の要素ごとの二乗の指数加重平均を用います.
具体的に書き下すと第 $t$ ステップでの更新は, $t$ ステップで得られたサンプルに対する勾配 $g_t$ から
$$ m_t = \frac{(1 - \beta_1) \sum_{i=1}^t \beta_1^{t-i} g_i}{1 - \beta_1^t} \\ V_t = \frac{(1 - \beta_2) \sum_{i=1}^t \beta_2^{t-i} g_i^2}{1 - \beta_2^t} $$
とおいたときに更新したいパラメータ $x_t$ を
$$ x_{t+1} = x_t - \alpha_t \frac{1}{\sqrt{V_t}}m_t $$
として更新を行っていきます. ここで $\beta_1, \beta_2 \in [0, 1]$ は勾配/補正係数の指数加重平均のハイパーパラメータで $\alpha_t \in {\mathbb R}$ は学習係数 (Learning Rate) です。 また $g_i^2$ は成分ごとの二乗を表しています. 即ち $(g_i^2)_j = (g_i)_j^2$ です.
このあたりは僕のスライドになってしまいますが https://speakerdeck.com/nyk510/que-lu-de-gou-pei-fa-falsehanasi?slide=7 あたりを見て雰囲気を掴んでいただけると, あとの話がスムーズに進むかなと思います.
この論文では主に $V_t$ について取り扱いますが, ルートをとって逆数を撮った形式を標準形 $\psi$ として扱います.すなわち
$$ \psi_t = \frac{1}{\sqrt{V_t}} = \sqrt{\frac{1 - \beta_2^t}{(1 - \beta_2) \sum_{i=1}^t \beta_2^{t-i} g_i^2}} $$
を以下では扱います.
SGD の warm start
SGD では学習の初期に小さな LR を使って更新を行い, ある一定のステップが立ったのちに通常の LR を使って SGD を使う, という戦略が取られることがあります. これを warm start といい, adam やその他の adaptive な学習法でも有効であることが確認されています.
warm start が有効な理由
ではなぜ warm start が有効なのでしょうか. 例として Adam でステップ $t=1$ の時を考えてみます.その時補正係数は
$$ \psi_1 = \sqrt{\frac{1}{g_t^2}} $$
となります.このとき仮定として勾配 $g_t$ が正規分布 $N(0,\sigma^2)$ から生成されているとすると $\frac{1}{g_t^2}$ は $\sigma^2$ でスケール化された自由度1のカイ二乗分布の逆数となります.(これを論文中では Scale-inv-$\chi^2 (1, \frac{1}{\sigma^2})$ と表記しています)
このとき $\psi$ の分散は
$$ Var[\psi] \propto \int_{0}^{\infty} x e^{-x} dx = \infty $$
となり発散します.この例で見たようにステップ $t$ が小さいときには補正項の分散は bound されません. したがって補正係数がとても大きい値を取る場合があり挙動が不安定になってしまいます.
論文中でも Figure2 で初期の step の更新で重みの分布が崩壊して学習が上手く進まなくなってしまう様子が可視化されています。
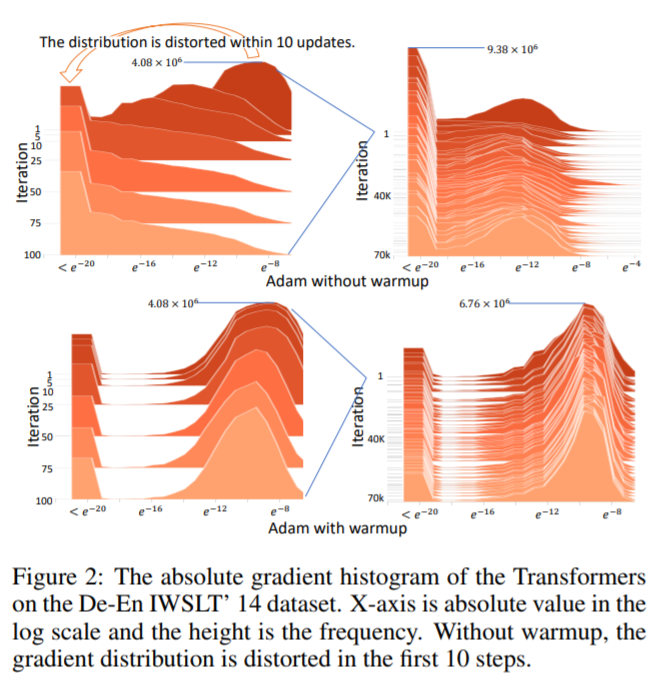
このような不安定性を抱えているため何らかの手段を講じる必要がありますが、その一つの手段が warm start です. warm start では $t$ が小さい領域では lr を小さくするため, 補正係数で bound されない分の上限を lr が変わりに行ってくれます.
このため安定した学習が可能になります. またステップが増えていくと $\psi$ の分散は bound されてくるので lr での bound は初期のステップの範囲だけでOKなこともわかります.
Adam の補正係数の分散
step $t$ が小さい時を考えます.このとき指数加重平均を行う際の重みの差分は $1-\beta_2^t$ 以内に収まります. $\beta_2$ は普通 0.99 程度なので $t$ が小さいときに差分が小さいことがわかります. このことから初期ステップでの指数加重平均は, おおよそ過去の勾配の平均をとったので問題がない, ということがわかります.すなわち
$$ \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} g_i^2}{1-\beta_2^t} \sim \frac{\sum_{i=1}^t g_i^2 }{t} $$
とみなせます.これを $\psi$ に当てはめると自由度 $t$ の Scaled inverse $\chi^2 (t, 1/\sigma^2)$ となります.
ではこの分布に従う $\psi$ の分散はどの様になるでしょうか? これを述べているのが Theorem.1 で結論を言うと 自由度を $\rho$ としたとき $\rho$ が増えるに従って分散は単調減少します. (正確には任意の $\rho > 4$ に対して上記が成立します)
これによってステップが増えていけば分散は縮小することがある程度保証されました. ではこの $\rho$ をどのように推定するのか? が次の話題になります.
自由度 $\rho$ の推定
$\rho$ を推定する際に使うのが Simple Moving Average (SMA) という考え方です.これは直近の $f(t,\beta_2) \in {\mathbb N}$ のステップで指数平滑移動平均を近似する, というものです.すなわち
$$ p\left( \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} g_i^2}{1-\beta_2^t} \right) \sim p \left( \frac{\sum_{i=1}^{f(t,\beta_2)} g_i^2 }{f(t,\beta_2)} \right) $$
を満たす, ということです.これを先の議論と合わせて考えると自由度 $\rho$ は $f(t,\beta_2)$ とみなせます.
この $g_i$ に対して $g_i = (t + 1 -i)$ であっても成り立ってほしい!ということで単に代入してやると
$$ p \left( \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} (t + 1 -i)}{1-\beta_2^t} \right) \sim p \left( \frac{\sum_{i=1}^{f(t,\beta_2)} (t + 1 -i) }{f(t,\beta_2)} \right) $$
を満たしている必要があるということになります. これを解くと*1
$$ f(t, \beta_2) = \frac{2}{1-\beta_2} - 1 - \frac{2t\beta_2^t}{1 - \beta_2^t} $$
を得ます.これを見ると $t \to \infty$ のとき $\rho_{t} \to \frac{2}{1 - \beta_2} - 1$ であることがわかります.(この値を $\rho_{\infty}$ とおきましょう) また $ \frac{2t\beta_2^t}{1 - \beta_2} > 0$ であることを考慮すると, $\rho_t < \rho_{\infty}$ であることもわかります.
$\psi$ の分散推定
では次に $\psi$ の分散がどの様になるのか考えていきます. 煩雑になるので飛ばしましたが Theorem.1 で分散を厳密に計算することができ, そのオーダーは $Var[\psi] = O(\frac{1}{\rho_t})$ であることがわかっています.(単に式変形するだけです) これと Theorem.1 の主張である「$\rho$ が大きいとき分散は小さい」を組み合わせると, 分散の最小値は $t \to \infty$ のとき, すなわち
$$ \min_{\rho_t} Var[\psi] = Var[\psi] |_{\rho_t = \rho_\infty} $$
であることがわかります(この最小値を $C_{var}$ とおきます.). すなわち $\rho_\infty$は計算可能ですから分散の最小値は見積もれる, ということです.
ここで, 学習が進むにつれて補正係数 $\psi$ のオーダーは変化しないことが望ましいことを思い出してください. これは補正係数が変わってしまうと, 最適な LR の値もかわってしまうためです.
したがって各ステップでの補正係数は, $C_{var}$ 程度の大きさになるようになってほしい, ということです. すなわちもともとの adam などの補正係数 $\psi_t$ に対して修正用の係数を $r_t \in {\mathbb R}$ かけて
$$ Var[r_t \psi] = C_{var} $$
が満たされていてほしいです.すなわち
$$ r_t = \sqrt{\frac{C_{var}}{Var[\psi]}} $$
を満たすように $r_t$ を選べば良いことがわかります. ではあとは計算するだけ, ですがこの係数を見積もるためには $Var[\psi]$ を知っている必要があります. これは解析的に計算することが困難なので ${\mathbb E}[\psi^2]$ の周りで Taylor 展開をした一次の部分を使ってやると
$$ Var[\psi] \sim \frac{\rho_t}{2(\rho_t - 2)(\rho_t - 4)\sigma^2} $$
を得ることができます.これと $\rho > 4$ のとき $Var[\psi]$ が単調減少であることを考慮すると $\rho > 4$ の範囲において
$$ r_t = \sqrt{\frac{(\rho_t - 4)(\rho_t - 2) \rho_\infty}{(\rho_\infty - 4)(\rho_\infty - 2) \rho_t}} $$
を設定することが良いことがわかります.
以上を記述したのが Algorithm.2 になっています.

はじめ各ステップで $\rho_t$ を計算します.この $\rho_t$ が大きいときは $Var[\psi]$ が小さいことを示していますから, Adam のような補正をかけることが正当です. 具体的には $\rho > 4$ の条件に合うかどうかを調べて当てはまった場合上記の補正を入れた勾配+補正項で更新します.
そうでない $Var[\psi]$ が大きいときには更新が十分に行われていないと判断して補正項を使わずに勾配のみを使って momentum で更新を行います.
ここで $\beta_2$ が小さいとき、具体的には0.6以下のときには $\rho_t $ がつねに4以下になる、ということに注意してください。
要するに $\beta_2$ があまりに小さすぎると $Var[\psi]$ は常に大きな値を取り続けると想定されるため Adam のような adaptive な更新を行うことは不適切 と判断される、ということです。この場合ずっと momentum のみの更新が行われます.
実験と考察
はじめに pure な Adam と SGD との比較を行っています.

この結果を見ると pure Adam にはどちらの条件でも勝っていることがわかります. *2
上記の実験は最も良いものを tuning した結果でしたが実際に実験する際にはどのようなパラメータでも学習がうまく進むことが望ましいですよね. それを調べるべくいちばん大事なパラメータ LR に対して学習がどのように変化するかが次のグラフです.
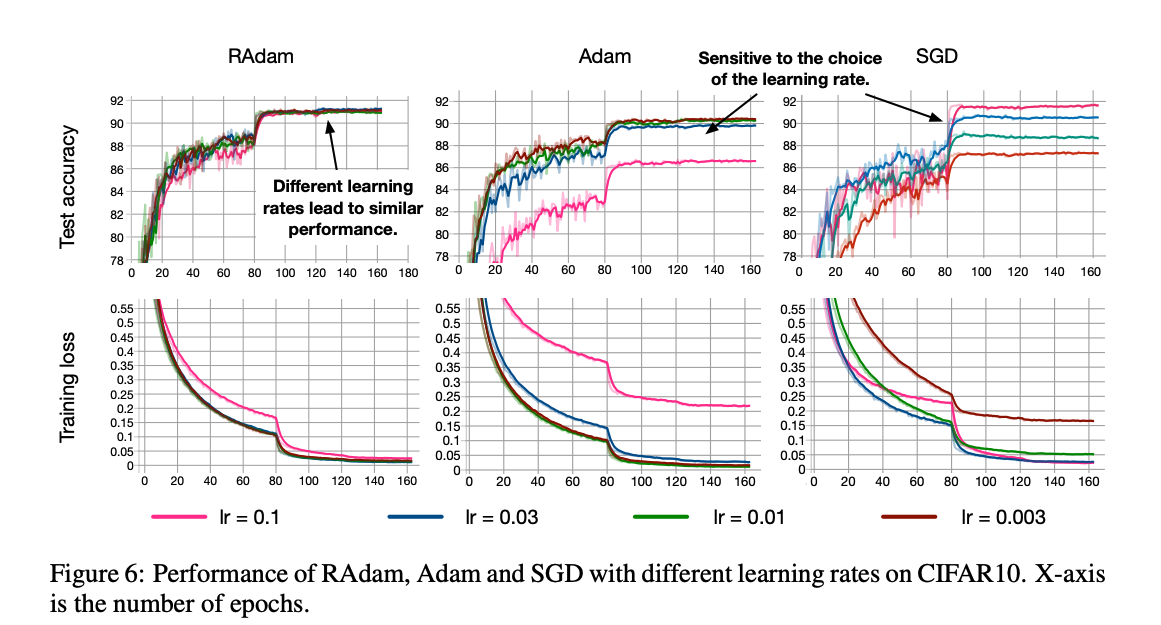
これを見ると RAdam がどのパラメータに対しても学習がうまく進んでいることが一目瞭然です.
次の実験はヒューリスティックな warm start と RAdam の戦略の差分を見るための実験です.
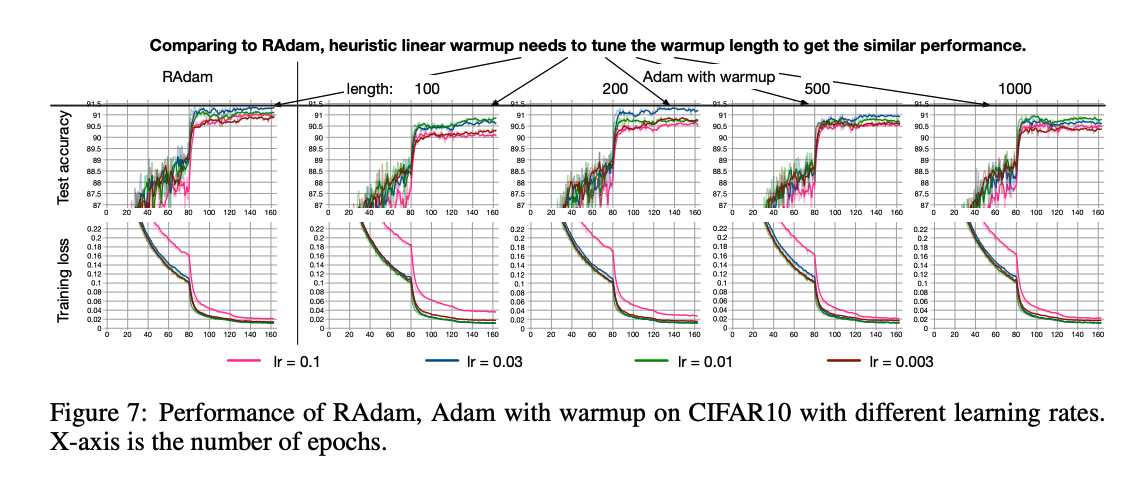
RAdam はいい感じに warm start をする方法, と捉えられますから RAdam が有効に働いていることが見て取れます.
他にも論文中での近似がうまくいっているかどうかの実験なども乗っています, が力尽きました.
結論と感想
Adam など adaptive な手法と同時に使われる warm start をうまく最適化のフローに取り込んだ RAdam という手法を紹介しました. 結果を見る限り warm start は必要ないような結果となっており, 職人芸的な LR 設定がひとつなくなって幸せなのかなと思いました.
また本論と関係ありませんが, この論文自体は microsoft のインターンの方が書かれたようでインターンでこれするんかというレベルの高さを感じました.
個人的な感想として以前紹介した Adabound が全く流行っていないのでこっちは流行ってほしいかなーと思いました.(warm start というヒューリスティックな方法をリプレイスできるというのは Adabound のSGDとの連続的な接続よりもインパクトがあるとも思いますので.)