項目応答理論の理論と実装
モチベーション: 変わった学校の定期テスト
ある学校では期末ごとに定期テストが開催されています。生徒は同じタイミングで同じ問題を解きます。この試験の結果から生徒の能力値を推定してほしいと依頼があったとしましょう。この場合すべての生徒は同じ問題を解いていますから、単純に問題の正解率を見たので十分でしょう。
ただ、この学校は大変に変な学校で、生徒ごとにランダムに違う問題が与えられているとするとしましょう。すると、正答率だけを見ているとたまたまかんたんな問題を与えられた生徒と、すごく優秀だけどめちゃくちゃ難しい問題ばかり与えられた生徒との区別ができませんから、おそらく不満が出てくるに違いないです。
このように、同じ問題を解いていない状態でも、解いている人の能力の比較をする枠組みの一つが項目応答理論と呼ばれるものです。
項目応答理論とは
項目応答理論は、複数のユーザがある問題を解いた結果 (正解 or 不正解) からそれぞれのユーザの能力や問題の難しさを推定する枠組みのことです。
身近な例だと TOEFL などが、この枠組をもとにユーザの得点を計算しています。
項目応答理論のモデリング
いくつかのバージョンがありますが、項目応答理論では、ユーザ $i$ の能力 $\theta_i$, 問題 $j$ の難しさ $\phi_j$, 識別度 $a_j$ としたとき, この問題をとけるかどうか?の確率 $q_{i,j}$ が以下の式で表されるとします。
$$ q_{i,j} = \sigma \left( D a_j (\theta_i - \phi_j) \right) $$
ここで $\sigma$ は以下で表されるシグモイド関数で、$D$はロジスティック関数を累積正規分布関数に近似するための定数です。
$$ \sigma (x) = \frac{1}{1 + e^{-x}} $$
シグモイド関数は入力の値が大きくなると 1 に, 小さくなると 0 に徐々に近づきます。すなわち問題が難しくなるとどんどんと解答できる確率がゼロになり、反対だと1に近づきます。反対にユーザの能力が大きくなると1に近づき、小さくなると0に近づきます。
識別度は問題が能力値に応じて解きやすくなる度合いを表します。例えば特定のレベルを超えたユーザはほぼ100%正答できるけれど、そうでないユーザはほぼ不正解になるような問題は、識別度が高いです。
最尤推定によるパラメータ推定
ユーザの正答確率がモデル化されたので、これを利用して今持っている正解・不正解のデータが得られる確率を計算しましょう。
今持っている回答結果が $N$ 個あり、そのうち $n$ 番目の解答が正しいかどうかを表す変数を $t_{n} \in \left\{0, 1\right\}$ としましょう。このとき、その結果の起こりやすさ(尤度) $p_n$ は
$$ p_n = \sigma (x_n)^{t_n} (1 - \sigma (x_n))^{1-t_n} $$
です。ここで、$x_n$ は$n$番目の問題のユーザを$i$, 問題を $j$ としたときに
$$ x_n = D a_j (\theta_i - \phi_j) $$
となります。これは、先程仮定したユーザが問題を解ける (正解する) 確率を、ベルヌーイ分布に適用したものです。
実際にはこれが$N$個ありますので、すべてを掛け算することで、回答結果データ $D$ 全体の尤度
$$ p (D | \phi, \theta, a) = \prod_{n=1}^N \sigma_n^{t_n} (1 - \sigma_n)^{1 - t_n} $$
となります。実際には数値安定の観点から対数をとったあと全体にマイナスをかけた、負の対数尤度 $f$ の最小化問題とします。
$$ \min_{\theta, \phi, a} f = - \sum_{n=1}^N \left\{ t_n \ln {\sigma(x_n)} + (1 - t_n) \ln({1 - \sigma(x_n)}) \right \} $$
この問題を解く方法はいくつかありますが、今回は勾配降下法 (勾配法) で解くことを考えます。勾配法では各ステップごとに目的関数のパラメータに対する微分を計算して、その方向へパラメータを更新します。今回最適化する対象となるのは $M$ 人のユーザごとの能力 $\theta_i (i = 1, 2, \cdots, M)$ と、$N$ 個の問題の難しさ $\phi_j$ と識別度 $a_j$ です。
はじめに、ユーザの能力に対する微分を考えて見ましょう。
$$ \begin{aligned} \frac{\partial f}{\partial \theta_i} &= - \sum_{n = 1}^N \frac{\partial f_n}{\partial x_n} \frac{\partial x_n}{\partial \theta_i} \\ &= - \sum_{n \in I} \left\{ t_n (1 - \sigma_n) - (1 - t_n) \sigma_n \right\} \cdot \frac{\partial}{\partial \theta_i} \left( D a_j (\theta_i - \phi_j) \right) \\ &= - \sum_{n \in I} (t_n - \sigma_n) D a_j \end{aligned} $$
ここで、ユーザー $i$ が回答している結果の集合を $I$ としました。
1行目から2行目で $\Sigma$ の対象が $N$ すべてから集合 $I$ になっているのは、ユーザ $i$ が関係しない結果に対して $\theta_i$ で微分するとゼロになるためです。またシグモイド関数に関する微分で成り立つ $\sigma' = \sigma (1 - \sigma) $ を利用していることに注意してください。
問題の難しさ、識別度についてもほとんどこれと同様に計算ができます。ここで、問題 $j$ に対する解答の集合を $J$ としました。
$$ \frac{\partial f}{\partial \phi_j} = - \sum_{n \in J} - (t_n - \sigma_n) D a_j $$
$$ \frac{\partial f}{\partial a_j} = - \sum_{n \in J} - (t_n - \sigma_n) D (\theta_i - \phi_j) $$
実際に推定してみる
コードは以下の gist を参照ください。
サンプルデータの作成
実際に推定をおこなうために、人工的に問題への回答結果のデータを作成します。
作成方法は以下のとおりです。
- まずユーザがもつ能力と問題の難しさと識別度の正しい値をランダムに生成します。
- 次にランダムにユーザ・問題を取り出して、正しい値をもとに反応応答理論で計算される確率 $p$ を計算し、
- 確率 $p$ で正解, $1-p$ の確率で不正解とするベルヌーイ分布をもとにして、解答が正解したかどうかを作成します。
ユーザの能力と問題の難しさは正規分布から、識別度は 0.5 ~ 2 の間の一様分布としました。問題の数は 100個, ユーザ数は 1000人 で回答結果の組み合わせは 1万件とします。
N_PROB = 100 N_USER = 1000 true_user_levels = np.random.normal(0, 1, size=N_USER) true_prob_levels = np.random.normal(0, 1, size=N_PROB) true_problem_disc = np.random.uniform(0.5, 2, size=N_PROB) results = [] for _ in range(10000): i, j = np.random.randint(0, N_USER), np.random.randint(0, N_PROB) p = calculate_correct_answer_probability(theta=true_user_levels[i], phi=true_prob_levels[j], a=true_problem_disc[j]) t = np.random.binomial(n=1, p=p) results.append([ i, j, t ]) results = np.array(results) df = pd.DataFrame(results, columns=["user", "problem", "answer"])
最急降下法による推定
はじめに勾配法によってパラメータを推定します。
# 問題の難しさ problem_levels = np.zeros(shape=N_PROB) # 問題の識別度 problem_disc = np.ones(shape=N_PROB) # ユーザの問題を解く能力 user_levels = np.zeros(shape=N_USER) D = 1.71 for step in range(10): _user_levels = df["user"].map(user_levels.__getitem__) _prob_levels = df["problem"].map(problem_levels.__getitem__) _prob_disc = df["problem"].map(problem_disc.__getitem__) sigma = calculate_correct_answer_probability(_user_levels, _prob_levels, _prob_disc) # 数値安定性のため極端な確率にならないよう min / max をきめて clip sigma = np.clip(sigma.values, a_min=1e-8, a_max=1 - 1e-8) diff = - df["answer"] + sigma print(objective(df["answer"].values, sigma=sigma)) # 問題の難易度の勾配 partial_prob_levels = diff * -1 * D * _prob_disc # ユーザの能力の勾配 partial_user_levels = diff * D * _prob_disc # 問題の識別度の勾配 partial_prob_disc = diff * D * (_user_levels - _prob_levels) # パラメータの更新 user_levels -= partial_user_levels.groupby(df["user"]).mean().values - 1e-8 * user_levels problem_levels -= partial_prob_levels.groupby(df["problem"]).mean().values - 1e-8 * problem_levels problem_disc -= partial_prob_disc.groupby(df["problem"]).mean().values
結果の可視化
正解・不正解の問題に対する期待正答確率の分布は以下の通りになりました。正解のとき確率1に近く、不正解のとき0に近いようにパラメータ更新ができていることがわかります。
次に問題・ユーザの真の能力と推定された能力を見てみます。
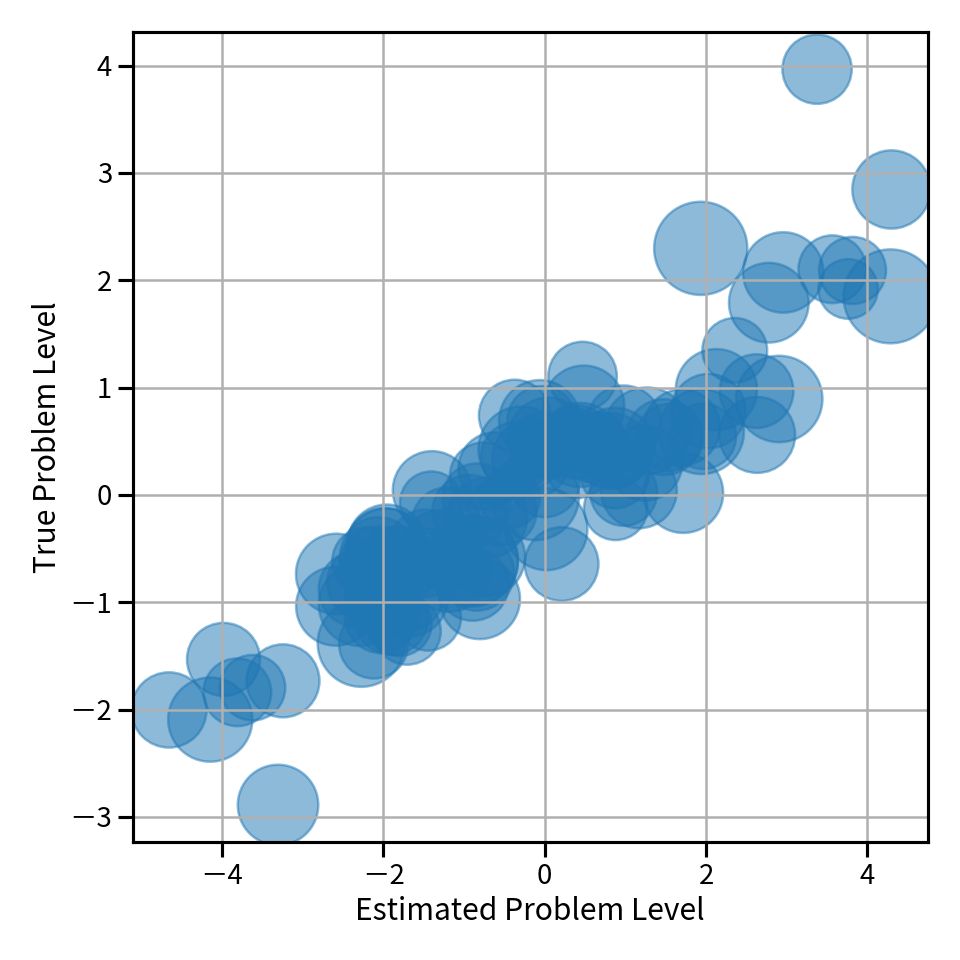
横軸に推定された問題の難しさ、縦軸に正しい問題の難しさを scatter plot として可視化したものが以下の図です。これを見ると対角線に並んでいて、概ね良い推定値が得られていることがわかります。

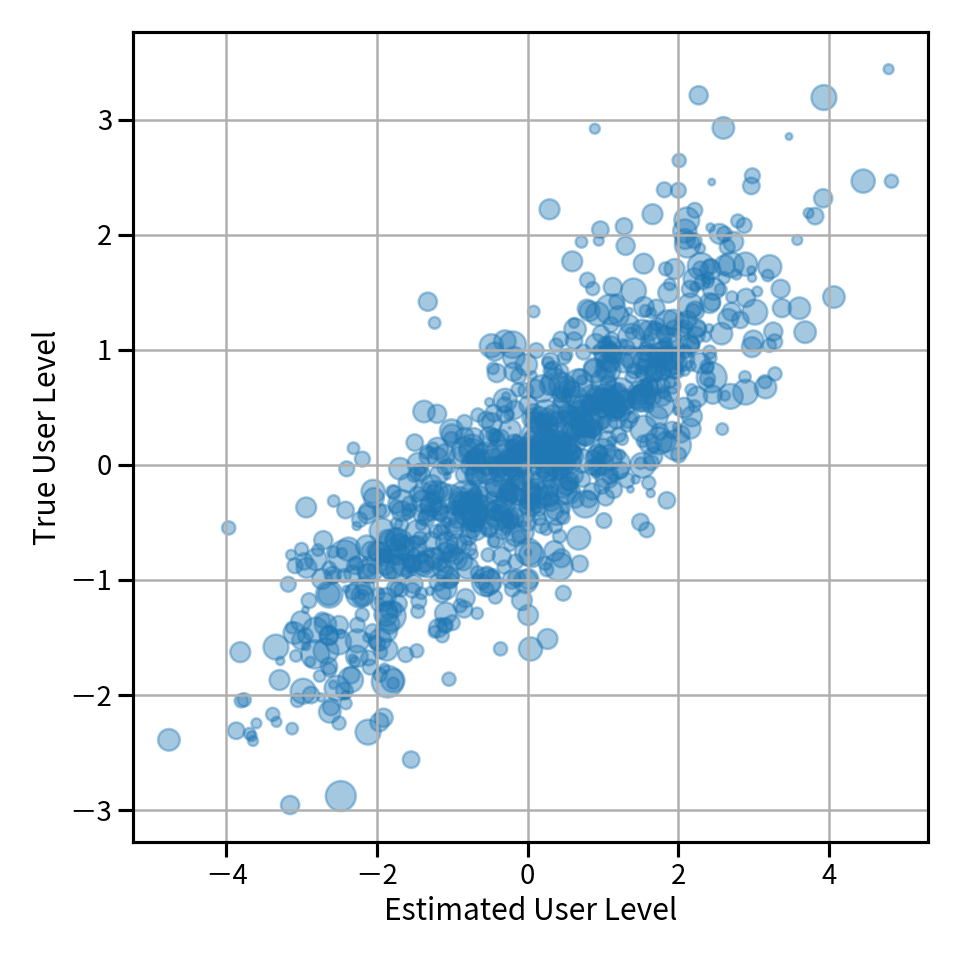
同様にユーザの能力に対しても plot したものが以下の図です。ズレはあるもののこちらも概ねよく推定できていることがわかります。

逐次的にデータが来る: Online Optimization の場合
先程の勾配降下法では、全体のデータを持っている前提で勾配を計算していました。実際の問題では、データが逐次的にやってくるような場合もあります。例えばオンライン英単語学習サイトがあって、ユーザが回答するたびにユーザの能力や問題 (この場合だと単語の難しさ) を更新したい、という場合などです。
このように逐次的にデータが来ることを前提とした最適化問題は Online Optimization と呼ばれます。これを解く方法の一つは、今やって来たデータだけで勾配を計算してパラメータを更新するというやり方です。これは、確率的勾配降下法とやっていることがほぼ同じですが、確率的勾配降下法ではデータセット全体はすでにあると仮定している一方 online optimization ではデータセット全体は手元にないと仮定している点が異なります。また online な設定ではデータは基本的に一回しか使わないですが、確率的勾配降下法では何度も繰り返してデータセットを利用して最適化を行います。
今回は回答結果データは1件づつやってくるとして、その結果についての勾配を使ってパラメータを更新します。
先程の実装と違い df.iterrows() でデータを1件づつ取得して、その勾配を計算している点が異なります。
from tqdm import tqdm # 問題の難しさ problem_levels = np.zeros(shape=N_PROB) # 問題の識別度 problem_disc = np.ones(shape=N_PROB) # ユーザの問題を解く能力 user_levels = np.zeros(shape=N_USER) D = 1.71 snapshots = [] for i, row in tqdm(df.iterrows()): _user_levels = user_levels[row["user"]] _prob_levels = problem_levels[row["problem"]] _prob_disc = problem_disc[row["problem"]] sigma = calculate_correct_answer_probability( theta=_user_levels, phi=_prob_levels, a=_prob_disc ) sigma = np.clip(sigma, a_min=1e-8, a_max=1 - 1e-8) diff = sigma - row["answer"] # 問題の難易度 partial_prob_levels = diff * -1 * D * _prob_disc # ユーザの能力 partial_user_levels = diff * D * _prob_disc # 問題の識別度 partial_prob_disc = diff * D * (_user_levels - _prob_levels) user_levels[row["user"]] -= partial_user_levels - 1e-4 * _user_levels problem_levels[row["problem"]] -= partial_prob_levels - 1e-4 * _prob_levels problem_disc[row["problem"]] -= partial_prob_disc * 1e-2 + 1e-6 * (1 - _prob_disc) if i % 100 == 0: snapshots.append([ user_levels.copy(), problem_levels.copy() ])
結果の可視化
さきほどの最急降下法と同じように問題・ユーザの推定結果と正しい値を plot したものが以下の図です。オンラインの設定でも、ある程度の推定ができていることがわかります。
ユーザの能力推定値の推移
ユーザの推定能力値は時系列に伴って逐次更新されます。実用上はステップ数が増えると正しい推定値を得てほしいですよね?
ステップごとの変遷を見るため、online の更新 100 回ごとに各々のユーザの推定能力値を可視化したものが以下の図です。
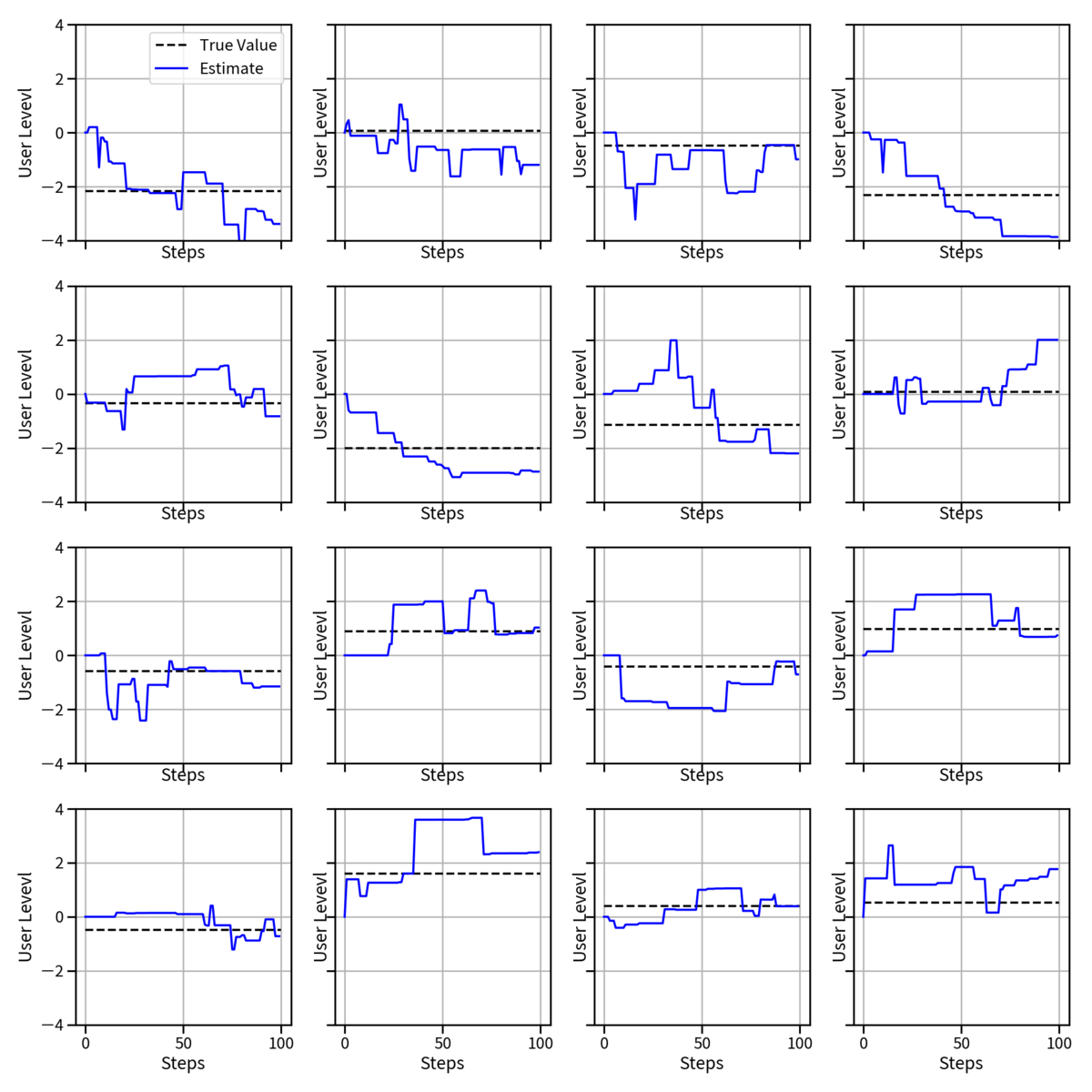
黒い点線がそのユーザの真の能力で、青い線がステップごとの推定値の遷移です。これを見ると大体の値は推定できていますがたまに大きくハズレた推定をしてしまっているものがあることがわかります。これは online 更新だと今までの回答履歴等を考慮していないため、ある難しい問題にたまたま正解したりすると急に値が増えたり逆に減ったりする可能性があるためです。
同じように問題ごとの推定値変遷を可視化すると以下のようになります。ユーザよりも問題のほうが数が少なくて、一つの問題あたりの回答数が多いため、ユーザの推定値よりも正確性が高そうであることが伺えます。

今回の問題設定の課題
今回のモデリングではユーザの能力が時系列に対してかわらないことを仮定しています。実際には時間がたつとユーザの能力や問題の難易度も場合よっては変動しますので、それらを組み込んだモデルを使う必要があります。 (今日はいったんここまで。気が向いたらまた調べる。)
ゼロ状態を考える
今回はコードを書く時の気持の話です.
たとえば配列 x の要素が 0.5以下の掛け算の値を取得する、みたいなことをしたいとします. たとえば以下の code で出来るような処理です (map つかおうやとかは置いておいて...)
import numpy as np def calc_factor(x): if x > .5: return None return x X = np.random.uniform(size=10) retval = None for x_i in X: # 要素に対して掛け算の値を計算 r_i = calc_factor(x_i) # 条件に合わない時何もしない if r_i is None: continue # 今までに値がなかったら今計算した値で置き換え if retval is None: retval = r_i # そうでない時掛け算して更新する else: retval *= r_i
このコードを書いた人は大変真面目なので値が全く存在しないゼロ状態のことを None と表現していることがわかります. それは
calc_factorで条件にマッチしない時 None を返していること- 計算結果
retvalの初期値が None であること
からわかりますね. ここで掛け算という計算(演算)を考えると 1 を書けても結果は変わりません. これは足し算でゼロを足してもゼロになるのと同じです. これを使うと上記は以下のようになるでしょう.
import numpy as np def calc_factor(x): if x > .5: # None を返さない return 1 return x X = np.random.uniform(size=10) # None で初期値としない retval = 1 for x_i in X: # 全部掛け算していく retval *= calc_factor(x_i)
だいぶスッキリ書けましたね! この掛け算という計算に対して何も変わらないものを考えてきれいにする、という操作は、配列の足し算 (concat) とか Object の要素の追加とか、他の概念の演算に対しても言えることです。
配列の追加
たとえば配列の要素から新しい配列を作成して全部まとめるみたいな処理があったとしましょう. map とかを使わないとすると以下のような感じ
def create_array(value) -> Optional[List]: if value > 5: return None return [value] * value new_array = [] for x in range(10): value_i = create_array(x) if value_i is None: continue new_array.extend(value_i)
配列の足し算に対して空っぽの配列 [] はゼロの意味を持っています。のでこれを使うと以下のようになります. すっきり!
def create_array(value) -> List: if value > 5: # なにもないとき None を返さない return [] return [value] * value # None で初期値としない new_array = [] for x in range(10): # 全部足し算していく new_array += create_array(x)
pandas.DataFrame の場合
たとえばですが pandas.DataFrame などもこれと同等の操作をできるようにAPIを設計してくれています. 例えば配列の値が 0.5 以下の場合にランダムにデータフレームを作成、横方向につなげる、ということをやりたいとしましょう (そんなん意味あるんかというのは置いておいて、機械学習の何かしらでありそうな感じになってきました.
import pandas as pd def create_df(x): if x > .5: return None return pd.DataFrame(np.random.uniform(size=(10, 4))) out_df = None x = [.3, .4, .6, .2, .3] for x_i in x: _df = create_df(x_i) # 値がない時なにもしない if _df is None: continue # 今までに計算している値が無かったら置き換え if out_df is None: out_df = _df # そうでなければ横に足し算する else: out_df = pd.concat([out_df, _df], axis=1)
実は pd.concat という操作に対して pd.DataFrame() はゼロを意味します(pd.DataFrame() を concat しても結果が変わらない). これを使うと、さきほどの数値に対する掛け算や、配列に対する足し算とおんなじようなことができます.
import pandas as pd def create_df(x): if x > .5: # zero 状態の data frame をかえす return pd.DataFrame() return pd.DataFrame(np.random.uniform(size=(10, 4))) # zero 状態の data frame を初期値とする out_df = pd.DataFrame() x = [.3, .4, .6, .2, .3] for x_i in x: # 全部くっつける out_df = pd.concat([out_df, create_df(x_i)], axis=1)
Django Q object の場合
Django というフレームワークの話です。Djangoではデータベースへのアクセスで、データを絞り込むクエリーを表現する Q instance というものがあります。
絞り込みは複数の and とか or をやりたいので、 Q にたいしても and / or を行うことで複数条件での絞り込みを表現できるように Django が設計してくれています。
例えば Q(hoge=1) & Q(huge=10) とやると hoge=1 かつ huga=10 のデータを検索してくれます。
じつは Q のAPIでは and /or の操作に対して Q() 渡しても結果は変わりません(!)
これは先ほどから見ていた「掛け算で1を掛けても結果がかわらない」という関係性と同じですね!
ですから、例えば複数の条件を or でまとめたいな−というとき、以下のようなコードは正しいのですが、
def calc_query_object(value): if value > 5: return None # 何らかの大変な条件の計算によって kwrgs が出来るとする kwrgs = {} return Q(**kwrgs) q_object = None # なんかたくさんの条件を or 条件でまとめたい for value in range(10): q_i = calc_query_object(value) if q_i is None: continue if q_object is None: q_object = q_i else: # or でまとめる q_object = q_object | q_i
ゼロ状態を意識して
def calc_query_object(value): if value > 5: # 空っぽの Q を返す return Q() kwrgs = {} return Q(**kwrgs) # 空っぽの Q で初期化する q_object = Q() for value in range(10): # 全部ガッチャンコ q_object = q_object | calc_query_object(value)
と記述したくなってきますね;)
面白いなと思ったら
実践Django / 一歩先に進むことが出来る本
このたび実践Django Python による本格Webアプリケーション開発を著者の芝田さんから頂きました。もともとこの本は買おうと思っていたので、大変嬉しくちょうだいいたしました。芝田さん、ありがとうございます:D
光栄なことに@c_bata_さんから実践Djangoを献本頂きました!🤩🤩🤩 ORMからテスト、認証認可やセキュリティ、更にDRFまであってタイトル通り幅が広い実践的な内容だなと感じました。チュートリアル+αの初見だとわかりにくいところまで丁寧に記載されていて、読み込んでいくの滅茶苦茶楽しみです🔥 pic.twitter.com/IPO2SA6174
— nyker_goto (@nyker_goto) 2021年7月8日
頂いてから1ヶ月弱ほどたってしまったのですが、この本を読んで思った良い所、どういう人に読んで欲しいかなど、僕なりの感想を書いていければなと思っています。
本当にざっくりとですが、本書の特徴的な部分を挙げるとすると以下の2つになると考えています。
- Django の難しいところをフォローしている
- Web開発に必要な実践的知識がいっぱい詰まっている
Django で詰まる一番難しいところを綺麗にフォローしている
Django は公式ドキュメントが大変に充実していて、チュートリアルもしっかりと用意されています。ただやはり英語がメインになるということと、そもそも Django がフルスタックなフレームワークであるため、そのしきたりに慣れていくのはなかなかに大変です。
本書では Section1 でステップバイステップで簡単なアプリケーションを実装していきますが、データの流れを可視化した図や、引数に対する意図やコメントなどが随所にあり、初めて実装をする人でも理解しやすいような構成の工夫が取られています。またその後のセクションで、テンプレートやORMなどの機能ごとに説明がありますが、こちらにも随所にフロー図やクラス図があり、Django の複雑なクラス構成や設定の構成が視覚的に理解できるようなっています。
Django を始めたてあるいは python をそれほど長く使っていないユーザは Django のクラス構成や設定部分の理解ができず、チュートリアルは写経でできるけれどそれ以上が難しい、ということがあると思っていて、僕もこのフェーズで相当に苦しんだ経験があります。本書はチュートリアルを本質から理解するための良い手がかりとなってくれるでしょう。
正直この図だけでも「あと3年早く読みたかったな」と思いました。
Web開発に必要な実践的知識がいっぱい詰まっている
次に言えるポイントは「Web開発に必要な知識がたくさんある!」という点でしょう。ここであえて[Web 開発に]と書いたのは、本書で扱っている内容が、単に Django の知識にとどまらないからです。それは例えばデータベース・認証認可・セキュリティ・テストなどが該当します。
例えばデータベースの部分を取り上げましょう。もちろんDjangoに関する本ですから、データベースへのアクセスをDjangoでどのように行なうかという内容は、当然触れられていますが、単に使うだけにとどまらず「では実際のSQLはどうなるか」、「そもそもSQLを効率的に実行するためにはどうすればよいか」、更にはクエリ解析によるパフォーマンス確認にまで言及されています。
正直単にDjangoを使うだけならばここまで書く必要がないだろうと思いますが、実際にWebアプリケーションを作る場合には、DBの動作を考えたり、その確認方法を知っていることは大事なことです。これらの知識は単に Django のチュートリアルをやり、ドキュメントを読んだだけでは身につかない実践的な内容です。
上記ではデータベースセクションを取り上げましたが、他のトピックに関しても同様で、単に Django で実装するにはどうすればいいか? の how to にとどまらない、アプリケーションを動かすための知識が詰まっています。個人的にはテストのセクションでどういう方針でテストを書けばよいかや、ユーザモデルの拡張方法とそれぞれのメリットデメリットなど実装していて悩むところに関して「こういう書き方もあるけど、こういうのあるしいいよ!」のような芝田さんの意見や気持ちが載っている部分がとても良いと感じています。時間差でペアプロしているような(?)感覚に近いかもれませんね。
どういう人に読んで欲しいか
本書は以下のような人に特に向いているなと感じました。
- PythonでWebアプリを作りたいなと思っている人
- Djangoはチュートリアルだけやってみたけれどその後が続かなかった人
- pythonの他のフレームワークでエンドポイント1/2個の単純なAPIは作ったことあるけれどそれ以上はない人
- Djangoを仕事で使っていてもうちょっとステップアップしたい人
1. PythonでWebアプリを作りたいなと思っている人
これから Web アプリを作ってみたい人には、大変オススメできます。最初は少し大変だと思いますが、Python の勉強をしつつ第一章をこなすだけでも相当力が着くと思いますし、公式ドキュメントを見てあれこれするよりも全体像がつかみやすいですので、その後の学習もスムーズになるではないでしょうか。
2. Djangoはチュートリアルだけやってみたけれどその後が続かなかった人
これは本書の特徴 1 で書いたように、難しいところをフォローしている部分がドンピシャで刺さると思います。図や適宜あるコメントなどを参考にしつつ、もう一度チャレンジしてもらえると大変学びがあるのではないかと思っています。
3. pythonの他のフレームワークでエンドポイント1/2個の単純なAPIは作ったことあるけれどそれ以上はない人
これはいつもはwebアプリケーションを作るのがメインではなくて、やったことがあるとすると簡単なレスポンスを返すアプリを Flask / Bottle でちょっと作ったことがあるな、ぐらいの人を想定しています。例えば機械学習の推論用サーバだけ実装、見たいな感じでしょうか。
自分もこのレイヤにいたことがあるのでわかるのですが Django はとてもハードルが高そうに見えるのですよね。実際フルスタックなフレームワークですから、覚えることも多く Flask などのようにさっくりとは作れないので、まあいいかで諦める… ということはママあるのだろうなと想像しています。また Web アプリケーションに必要な知識もそこまで持ち合わせていないので、やりたいことを実現するためにはそもそもどうやったら良いのかわからないし普通どうやってやるんだろう、と思っている人が多いのではないでしょうか。
そういう人がちょっと DB との接続もあってユーザ認証とかもあるアプリをやりたいな! と思った時、Djangoの初心者に向けた内容から実践的Webアプリの内容まで含まれている本書は、まさにピンズドな選択肢と言えるでしょう。諸手を挙げておすすめできます。
4. Djangoを仕事で使っていてもうちょっとステップアップしたい人
最後のこれは私です。なのでみんなが該当するとは言わないのですが、読んでいてなんとなくの理解で使っていた部分や知らない部分など見て相当に勉強になりましたし、Django の勉強の意欲をもらえてとても楽しく読んでいました。(完全に感想になってしまった)
まとめ
どんな人が読んでも、一歩先に進むことができる大変良い本です。
良え本や。
github にサンプルコードがあるようですので、購入前に中身の雰囲気を知りたい方はこちらも参考にしていただくのが良いかもしれません。*1

Django Congress 2021 に参加しました!
2021/07/03 に開催された Django Congress に参加しました。とても有意義なお話を沢山拝聴でき勉強になりましたし非常に楽しかったです! ありがとうございました!
以下各発表の自分のメモ書きになります。(スライドは随時追加予定です)
- 公式ページ: https://djangocongress.jp/
- connpass: https://django.connpass.com/event/214451/
Django 3.2 ASGI対応 - こわくない asyncio 基礎とasync viewの使い所
Junya Fukuda san
- Awsgi / Async View の説明
- スライドわかりやすい〜
- async / await のためには ORM の async 対応も必要
- 現状はまだできてない。
- 非同期ORM対応の検討中らしい
note
- 雑な理解しかしていなかったので参考になった。
- 非同期ORM、楽しそう。入ると、効率がアップすると思うのだけれど、どのぐらいの改善度になるのかなー?
RLSを用いたマルチテナント実装
Takayuki Shimizukawa san
マルチテナントのメリット
- 各ユーザが同じリソースを使えるので無駄が少ない
マルチテナントのデメリット
- データが混濁する可能性がある
- 気合でデータ混濁を防止するのは無理
- データ混濁をしないような仕組みづくりが必要
マルチテナントの方法
| name | DB | アプリ |
|---|---|---|
| スタンドアロン | 分離 | 分離 |
| テナント単位DB | 分離・準分離 | 共有 |
| シャドーマルチテナント | DB共有 | アプリ共有 |
DB準分離
- メリット
- デメリット
- テナント数が増えたときのメンテナンスコストが高い
- migration をテナント数だけ実行する必要がある
- 例えば 30[s] の migration で 5000 テナントだと1日以上かかる 😭
- テナント数が増えたときのメンテナンスコストが高い
DB共有
- メリット
- メンテコストが低い
- デメリット
- 混濁おこるかもよ → RLS を使って行レベルアクセス権限を設定する
RLSとは
- row level security (行レベルセキュリティ)
- 行単位でアクセス権を制御する DB の機能
RLSの仕組み
- ROLE:
- データ・ベースのテーブル・行権限を決めるもの
- 対応の行と、今アクセスしているユーザの role との一致で、行単位でのアクセス権限が制御される。
- たとえば tenant 列を role として設定して role=1 のユーザでアクセスすると tenant = 1 の行だけしか見えない
- 権限の扱われ方
- RLSがあるとテーブルアクセス権と行アクセス権の概念が別に存在する
- テーブルへの select 権限があっても RLS がないと何も見えない
- POLICY を設定するとマッチする行だけが帰ってくる様になる
- RLSがあるとテーブルアクセス権と行アクセス権の概念が別に存在する
Djangoでどう実現する?
- Django では DB接続のユーザを切り替えるのは難しい
- ユーザは変えずに set role を使ってセッションのユーザを付与する
- Django のライフサイクルに role 設定を仕込む
- テナント作成時に新しい role を追加
- post_save の signal でテナント作成
- middleware でテナント判断
- ログインユーザに応じた role を付与して query 発行するようにする
通常より気にする必要があるポイント
- クエリ負荷の上昇は、もちろんある。
- 負荷対策をよりシビアにする必要がある
- コネクションを分けるのはできない
- DBの上限接続数が 100 以上にできない。したがってテナントごとコネクションは難しい。
- 負荷分散
- テナントごとにクエリを利用するリソースを分けたい → Citus / Hyperscale 利用を検討する
- 特定テナントごとに別ノードで分散処理できる (テナント1は node1 で実行などできる)
DB共有デメリット対策
- role設定忘れ内容に
- バックアップ方法
- PITRをテナント単位で行う方法
- 負荷分散リソース
質疑
- 単体テストはどうする?
- 今はコンテナあるので、テストのときもポスグレつかえはOK
- role を定義しているカラムに index 貼れば速度は改善する?
- 調査しきれていないが、単に数値を設定するのではなくテキスト付与すると良くない
Note
- 各設定方法のメリットデメリットが整理されていてありがたい。
- テナント形式のアプリはたまにあるので参考にしよ。
Djangoでのプロジェクトだって型ヒントを運用出来る!
みずき-san: https://speakerdeck.com/mizzsugar/djangodefalsepuroziekutodatutexing-hintowoyun-yong-chu-lai-ru
djang-stubs
機能
- model に存在しない attribute
- django の queryset
- どの model の query かを設定できる
models.Queryset[HogeModel] - None or model:
Optional[HogeModel]
- どの model の query かを設定できる
型ヒントのよいところ
- 安心してリファクタできる
- 修正の多いビジネスロジック層に導入して安心安全にする
どこから始める?
git pre-commit フック
- メリット
- CI が不要
- デメリット
- コミット内容と関係ない部分もエラーになる
- エラーがあるとき、強制的に commit をする方法もあるがオオカミ少年的になる
- 結局利用しないことに決めた
- 途中から導入したゆえの大変さ
- 最初から入れていたらやっていたかも
--strict option
- mypyはデフォルトでは4つを指摘する
- strict にするとより細かい内容も指摘する
- django で strict は必要?
- django のコードと strict の相性が悪い
- これは解決したみたい。
- デフォルトの内容でも十分と判断して strict しないように
- django のコードと strict の相性が悪い
CI をいつ入れる?
- django 関係ない utils module にたいして type がついてから
詰まったポイント
- AbstractUserModel の継承時の問題
- [memo] おそらく class の継承全般で発生する問題かな?
- field と同一名の method 定義
- related object does not exist がない
- Queryset.value_list で django-stubs の型が django から消えてる
質疑
- チームからの反対はなかった?
- もともと別のプロジェクトに型をつけていた。その時のメンバーは好意的にやってくれていた。
- 次のプロジェクトにも入れていこうという流れにつながった
Note
- 型設定のチーム導入の話まで踏み込まれていて学びがおおい
- mypy 使えてないのでちいさいとこからこつこつ入れていこうと思いました。
Django管理サイトをカスタマイズする前に教えてほしかったこと
akiyoko-san: https://speakerdeck.com/akiyoko/how-to-customize-admin-djangocon-jp-2021
Django 管理サイト
- みんな使ってる管理サイト
- 困りごと
- カスタマイズが大変という意見が多い
基本仕様
- ログイン条件
- is_staff / is_active が true
- permission
- モデルごと・操作ごとの permission が必要
カスタマイズの難易度
- かんたん
- django の用意してくれているカスタム方法を使うやり方
- 全体をかえる → AdminSite
- モデルごと → ModelAdmin
- 難しいこと
- template のカスタマイズ
- css のカスタマイズ
template のカスタマイズ
- 優先度が高いディレクトリに編集したいテンプレートを設定する
- 直したい部分だけ継承して編集・場合によっては全体まるっと持ってくることも可能
- [tips] 実際にどのようなテンプレートが使われているかは django-debug-toolbar の template から確認できる
CSS のカスタマイズ
- 静的ファイルの優先順位を知る
- template 同様に、ファイルの優先順位があるので、自分が設定したいものが上に来るように適宜設定する。
- 全体の編集:
- 管理サイト本体の extrastyle block を override して設定
- extrastyle は main の css のあとに読み込まれるので優先度高く読み込まれる
- 設定方法
- 新しいファイルを読み込むように overide
- 静的ファイルの場所が優先度が高くなるようにしておく
- 管理サイト本体の extrastyle block を override して設定
- モデル部分のみの編集:
- model admin の media.css を利用する
admin site のテスト方法
- そもそも断片的なコードしかないのでどういうテストをすればよいかが自明ではない
テストの方法
Note
未経験者のDjangoでの個人開発
大変だったこと
- ORM
- 認証周りなどなど
なんでそうなっちゃったか
- コードと挙動の関係性理解が欠如しているママまえに進んでいた
- 参考にして良いものがわからなかった
- わからないことがいっぱいあって焦っていた。
反省点
- コピペでチュートリアルをやっていた
- 中身を理解せず、動かすことに注力していた
- 動かす楽しさは大事だけれど、長期的に見て中身を理解することが大事
- エラー内容の本質理解の欠如
- なんとなくで理解していた
- エラー文をちゃんと読まずに表面的対応になってた
良かったこと
- 設計の意識
- git を CLI から使う
反省から学んだこと
- 非公式の情報を参考にするときは以下を気をつける
- 前提条件が欠かれているのか
- 中身を自分が理解できる説明か
- 公式ドキュメントを大事にする
- 初歩を大事にして、少しづつ応用へと向かっていく
- 疑問点をそのままにしない
学習はとにかく時間を書けるしかない
質疑
- なんで django にしたの?
- 友達がやっていたのでやってみた
- 振り返りの考え方ができるのはなんでですか?
- スポーツをやっていて、その中で人と比較して自分を省みることをまなんだ
- どういう本があったら嬉しい? どういう内容があると嬉しい?
- socail auth の設定はどのようにやった?
- 考えてもわからなかったので質問して解決した
- 質問をするときに情報をまとめる作業で解決することもあった
- 今後の興味は?
- チーム開発のやり方・テストコード
- 機械学習もやってみたい
note
- 何ができていなくて、何をしたらいいのかが言語化されていて素敵
- 17歳すごい
Securing Django Web Applications
Gajendra Deshpande san: https://speakerdeck.com/gcdeshpande/securing-django-applications
Note
- こういう情報はどうやって仕入れているのかなーと気になったのですが聞けず… mmm
- 資料の量がすごい。読み返そう。
Django & Celery in production
Masataka Arai san: https://speakerdeck.com/massa142/django-and-celery-in-production
タスクキューとは
- producer
- task を作って broker へとパスする
- task: 非同期で実行する処理のひとつのまとまりのこと
- queue: task を入れる入れ物
- task を作って broker へとパスする
- broker
- もらった task を queue に入れる
- queue に入っているタスクを consumer へと渡す
- consumer
- 実際に task をおこなう (celery worker)
タスクキューにはいいとこ悪いところがあるのでそれを理解して使う必要がある (ex: メール送信などなど)
- メリット
- 時間がかかる処理を非同期に逃せる (リクエスト早くなる)
- 処理が別れているのでスケールしやすい
- エラーがあってもリトライできる
- デメリット
- 複雑化
- 監視・ログの考え事がふえちゃう
- 処理の遅延が大きくなる可能性がある
- 複雑化
celery 以外のやり方もあるよ
- RQ
- FaaS: lambda と SQS
気をつけポイント
- モデルインスタンス渡しがちだけど、古いデータになることに注意
- 実行時に最新の instance を取得したいのであれば pk とかを渡すように
- テスト時には同期的に実行するオプションを入れる
リトライ設計の心得
- 復帰可能なエラー以外は投げっぱなしにする
- 復帰可能なものに関しては…
- 無限にくりかえす
- 冪等性を担保して何回も実行する
- 運用でカバーする必要があるものに関しては DB に入れる
- 目的
- ダウンタイムを少なくする (障害を回避することではない)
- 壊れてもいつでも戻れるようにしてしなやかなシステムにする
- no ops: https://www.slideshare.net/hiromasaoka/15-noops
タスクへの設定方法
- 単純なリトライ
- autoretry_for
- 複雑なリトライ
- retry_when_retriable に自分で関数を設定
- だめだった理由ごとにリトライの方法を書いていく
- mysql のロック などなど
- エラーハンドリングの育て方はどうするんだろう
ロギング
- django-celery-results
- celery の task protocol = 2 だとネストした dict の深度が 3 になるので注意
- 運用カバー
- django-admin から以上設定のものを再起動できるようにしておく
- 監視
celery inspectを使って待ってるタスクを見る- 実行待ち時間が長くなると slack に投げる、など
本番環境の更新
- task 更新時
- タイミングのずれで昔の引数で呼び出される可能性がある
- 引数には必ずデフォルト値を設定 & kwargs でハンドリングできるようにしておくことで新旧の呼び出しに対応する
- task 削除時
- 昔のサーバーから call される可能性がある。
- celery はそのままで app サーバーだけ更新する。
Note
- ナイーブに app と同時に celery server も更新すると良くないのとか考えてなかった。CI 組み込むときも気にしないとな。
理解して使いこなすDjangoのForm機能
フォームの vaidation を少し直すとなったときでもいろんなパラメータがあってよくわからない。
- django shell をつかおう
- form を shell から見ることで理解が深まる & テストコードも自然に書ける
Form の構成要素
- bound field
- html の作成を担当
- widge
- form の部品をレンダリングする
- error
- form.errors にエラーが代入される
- form から見ると widge の名前が key に errors の配列 (List[Error]) が value に入って取得できる
- 複数の field にまたがった validation をする場合
- form.clean に記述する
super().clean()を call して各要素の validation を終わったあと validation がおわったデータを使って validation のロジックを記述する- ここでエラーになると none-field error になる
- 特定の key にエラーを入れることもできる (add_errors)
- 一つの field で validation
- form のコンストラクタに validators を追加する
Note
- form の構成から細かく説明いただいていて大変参考になる。
スポンサーセッション
- (株)日本システム技研さん
- 設立 昭和51年7月
- 会場コストのスポンサー。大変ありがたい。
- 2014年から会社として Django を使おうという流れできていて、当時と比べると今はたくさん日本語の情報が出ていて、隔世の感とのこと。そうなのかー!
まとめ
いろんな新しいことをしれてとても楽しかったです! 開催運営のみなさまありがとうございました!