Websocket の認証 (Authentication) について考える
はじめに
以下は Websocket 初心者の筆者が、認証 (Authorization) 付き Websocket 通信を行なうためにどうやったら良いのか、を調べたメモ書きです。 日本語や英語で調べても、どんなやり方があって実際どうやればいいのか、まとめて書いているページが見当たらなかったので調べて見つかったそれっぽいものを書いています。
実運用などしているわけではなく完全な初心者です。間違っている内容もある可能性が高いことを前提のうえで読んでください。
そもそもの話
認証とは
リクエストしているユーザが何者なのかを判定する操作のこと。今回考えるのはウェブのAPIである。この場合APIへリクエストを送ってきているユーザが誰かを判定することが相当する。
通常のエンドポイント (http / https) であればリクエストのセッションを使ったり、あるいは JWT (Json Web Token) を header に入れてリクエストしてもらいサーバー側で header を解析して、正当な Token であることを確認できた時だけその token に記録されているユーザとみなす操作が該当する。
Websocket とは
サーバーとのやり取りの方法 (プロトコル) の一つ。並列な概念が http。
httpと異なる点として
- 双方向通信が低コストで行える。
- はじめにコネクションを確立し、2回めからはコネクション上で通信を行なうため通信が軽い。
- ステートフルである(今までのリクエストに依存して結果が変わる。反対にhttpはステートレス。)
と言ったことが挙げられる。
webcoket が活躍するのはイベントが発生した時に、クライアントとサーバーとで双方向にやり取りを頻繁に行いたい場合である。
例えばチャットアプリを考えよう。自分が発言した内容がサーバに送られて保存されることはもちろん必要であるが、他のユーザが発言した時にそれをリアルタイムに知りたいであろう。この場合 http であるとクライアント側からサーバーに一定時間おきに新しいメッセージがないかどうかを確認する方法しか取ることができない。また http の通信は重たいので、サーバのコストも大きい。
一方で websocket では新しいメッセージがサーバに届いた時、サーバ側からクライアントへ「メッセージが着ましたよ」という通知を送ることができ、クライアント側からいちいち確認をすることなく、最新のメッセージの有無を確認することができる。
Websocket に対しての認証
websocket ではコネクションを確立する必要があるが、一般のアプリケーションでは誰にでもコネクションを張られると困る場合が多い。
たとえば上記のチャットで言うと、後悔されていないルームであれば、許可された人しか入れないようにしたいだろう。この場合はじめにリクエストしている人が誰なのか (== 認証)を確認してから、そいつがルームへのアクセスを出来るかどうかを確認する (== 承認)する手続きが必要である。したがって、コネクションを張ってデータを流すタイミングまでに必ず認証のフェーズを踏む必要がある。
解決する方法の一つとして WebSocket のセキュリティ#認証/承認 にて提案されているのがチケットベースの認証方法である。以下に抜粋する。
- クライアント側のコードが WebSocket を開くよう決定すると、承認「チケット」を得るため HTTP サーバーに接続します。
- HTTP サーバーはこのチケットを作成します。チケットに一般に含まれるのは、何らかのユーザー/アカウント ID、チケットを要求しているクライアントの IP、タイムスタンプ、そして必要となる他のあらゆる内部記録管理です。
- サーバーはこのチケットを (データベースあるいはキャッシュ内に) 保管して、クライアントにも返します。 クライアントは WebSocket 接続を開き、この「チケット」を初期ハンドシェイクの一環として送ります。
- するとサーバーはこのチケットを比較し、ソース IP を調べて、チケットが再使用されておらず失効していないことを確認して、他のあらゆる権限チェックを行います。すべてがうまくいくと、今度は WebSocket 接続が検証されます。
要するにユーザを同定できるチケット (以下では token と呼ぶ) をAPIサーバからもらい、websocket の通信時にそれを使ってユーザを特定する、という流れになる。
このチケット型の方法を使おう!となって実装しようと思った時、やり方としては大きくわけて2つの方法があると考えられる。
- コネクション確立タイミングと同時に token を送信する方法
- コネクション確立後に token を送信する方法
1. コネクション確立タイミングと同時に token を送信する方法
これは websocket の通信が始まる段階でサーバーに認証に必要な情報を送信する方法である。通常の rest api のように Authorization Header を使えば OK に見えるが、残念ながら Websocket には header が存在しない。ため他の方法を使う必要がある。
1.1 URL の query parameter を使う方法
これは単純に Websocket の URI にクエリパラメータとして token を載せる方法である。
WebSocket("wss://.../?token=my-awesome-token")
- メリット
- 簡単に実装できる
- デメリット
- ウェブサーバーの log には uri が記録される場合が多いため、利用する token の有効期限などに注意する必要があると思われる。
とても単純で、サーバ側の処理も比較的簡単にかけるためこの方法が紹介されている例はウェブ上を検索するといくつか見つかる。
- WebSockets - Part One (websocket でアプリケーション作ろうのチュートリアル。query parameter に入れてる。): https://testdriven.io/courses/real-time-app-with-django-channels-and-angular/part-one-websockets-part-one/
1.2 Sec-WebSocket-Protocol を使う方法
これは Websocket の protocol option に token を設定する方法である。
WebSocket("wss://...", "awesome-token")
- メリット
- URL をみても乗っ取りはできない。
- デメリット
- なんだろう… 少なくとも query parameter で送るよりは見えにくいし安心感はあるきはする。とはいえ wss でないと header 部分は見えちゃうしお気持ち程度か。
- token の有効期限に応じてコネクションを閉じるとかはかかないと駄目かも。
2. コネクション確立後に token を送信する方法
これは一度コネクションは確立してしまって、次の送信で token を送ってもらいその情報を元にして認証を行なう方法。twitter でぼやっとつぶやいたら、教えてくれました。
WebSocket の接続を開いた後のメッセージのやり取りでペイロードとして送るやり方もありそうですね。使い捨てとはいえセッション ID にも近い概念なので、query parameter で送るよりもそちらの方が直感的には安全マージンが大きそうな気がしました。
— もみじあめ (@momijiame) 2021年5月11日
- メリット
- セキュリティ的に安心安全: token の送信は connection が張られたあとに行われるので、URIなど見やすいログには残らない
- デメリット
- 実装がめんどくさいかもしれない(お気持ち程度)
- Websocket ではコネクション時の動作が特別なので、コネクション時に動かす関数がサーバ側のライフサイクルの一つとして定義されている場合が多い。したがってコネクション時の判定はわりとロジックとして書きやすい。
- 一方メッセージ送信の最初だけ判定となると、メッセージ受け取り部分で条件分岐などをして認証を行なうロジックを動作させる必要があり、若干冗長になるかもしれない (お気持ち程度だけれど)。までもメリットのほうが強いよね。
- 実装がめんどくさいかもしれない(お気持ち程度)
ちょっと違うけれど、例えば Authenticating Websockets では各メッセージごとに認証を通す方法 (Authentication In Each Message のセクション) なども紹介されている。
The second strategy is to include authentication in each message. In this model the client adds a property to the sent object that includes the JWT.
この場合だと token の有効期限とかは自然に対応できそう。もちろん毎回チェックするのでサーバのコストは高くなるのと、受け取り手のチェックはできない (今つながっているやつらは信じるしかない) ので、送る方だけ厳密になるイメージかな? これも割と良さそう。
参考資料
- WebSocket サーバーの記述: https://developer.mozilla.org/ja/docs/Web/API/WebSockets_API/Writing_WebSocket_servers
- Websocket の通信がどのように行われるか平易にかかれたドキュメント。
- WebSocket のセキュリティ: https://devcenter.heroku.com/ja/articles/websocket-security
- Websocket をつかったアプリケーションを構築する場合にやってはだめなことが記載されている heroku のドキュメント。heroku を使わない場合でも気にしないと駄目なことが書いてあるので、助かります。
特徴量選択アルゴリズム HSIC Lasso とその周辺を調べた
先日、特徴量選択についてツイートしたところ Kaggle Master のアライさんに「HSIC Lassoはまさにぴったしなんではないでしょうか?」と教えていただきました。
お、となるとHSICLassoはまさにぴったしなんではないでしょうか?https://t.co/Ezigm9OriK
— Hidehisa Arai (@kaggle_araisan) 2021年3月28日
HSIC Lasso は直前にあった統計学勉強会#2でのアライさんの発表資料でも取り上げられていたものです。 統計学勉強会は twitter から眺める程度で見ていたのですがとても盛り上がっていて楽しそうした。次回は是非参加したいと思っています🔥
統計学勉強会#2 from Hidehisa Arai
www.slideshare.net
自分がこの分野に疎いのでただ使うだけじゃなくて中身の気持ちとか似た手法についても調べたいなと思い、いろいろと調べてみました。以下は HSIC Lasso を提案した論文 High-Dimensional Feature Selection by Feature-Wise Kernelized Lasso とそこで引用されている論文・資料などをまとめたものになります。
おことわり・説明していないこと
- HSIC に関する詳しい説明
- HSIC Lasso 以外の特徴選択手法に関する網羅的な説明
- 論文中で触れられているもの程度しか紹介していませんので、網羅性はあまりないです
- また筆者は特徴量選択手法に詳しい人間ではありませんので、誤りがあるかもしれません。おや?と思ったひとは元論文にあたっていただけると幸いです。
特徴量選択とはなにか
ある予測対象である目的変数 $y$ と、それに紐付いた $d$ 次元の特徴ベクトル $x \in \mathbb{R}^d$ があり、それが全部で $N$ 個ある状況を考えます。
一般的な機械学習では $x$ を入力とした時に $y$ を説明するような関数 $f$ を作成することが目標ですが、それとは別に $x$ のうちで有効なものはどれかを知りたい場合があります。例えば特徴量を観測するのがとてもコストが高くて、一部だけでなんとかやりたい時など、たくさんの特徴のうちどれが意味があるものかを知りたい状況は良くあります。
このように、入力された特徴量 $x$ のなかから、目的変数 $y$ を説明・予測するのに有効な特徴量の組を選ぶことを特徴量選択とよびます。
Lasso
もっとも有名な特徴選択アルゴリズムの一つに Lasso があります。Lasso は以下の最適化問題として記述することができます。
$$ \min_{\alpha \in {\mathbb{R}}^d } \frac{1}{2} || y - X^{\rm T} \alpha ||^2_2 + \lambda || \alpha ||_1 $$
ここで $y \in \mathbb{R}^n$、$X = [x_1, x_2, \cdots, x_n] \in \mathbb{R}^{d \times n}$ は目的変数・特徴量をデータの数 $n$ だけ並べたベクトルで $\alpha \in \mathbb{R}^d$ は特徴量の重みです。
第一項はデータへの当てはまりを表していて、第二項は正則化(重みへのペナルティ)になっています。Lasso は正則化項として L1 ノルムを使っているため L2 をつかう Ridge に比べてスパースな解が得られやすいというメリットがありますが、非線形性を捉えることができないという欠点を抱えています。
Instance-Wise Non-Linear Lasso
非線形性を捉えられるように改良したものとして、データ点ごと (instance-wise) な Lasso Instance-Wise Non-Linear Lasso があります。
$$ \min_{\beta \in {\mathbb{R}}^n } \frac{1}{2} || y - A \beta ||^2_2 + \lambda || \beta ||_1 $$
ここで $A \in \mathbb{R}^{n \times n}$ は $A_{i,j} = \phi(x_i)^{\rm T} \phi(x_j)$ で表される行列で $\phi(\cdot): \mathbb{R}^d \to \mathbb{R}^{d'}$ は特徴量 $x$ を $d'$ 次元のベクトルへ変換する非線形関数です。Lasso とデータへの当てはめる部分が異なっていて、特徴 $x$ を非線形変換したあと、すべてのデータ点との距離 (内積) へと変換する処理が入っています。
$\phi$ という非線形関数を組み込むことによって、特徴量の線形な関係以外も記述できるようになりますが、決定される重み $\beta$ は $n$ 個のデータ点に対する重み付けになっています。
要するに、どのデータ点からの距離が重要かはわかる (SVM でいうところの Support Vector がわかる ) のですが、どの特徴量が大事か? には答えてくれませんから、特徴量の選択としてもちいることはできません。
Feature-Wise Non-Linear Lasso (FVM: Feature Vector Machine)
上記のデータごとの非線形性を特徴点へと拡張したものが Feature-Wise Non-Linear Lasso (FVM) です。FVM はデータの空間ではなく、データ数 $n$ の次元からある別の次元 $p$ へと変換する非線形関数 $\phi(\cdot): \mathbb{R}^n \to \mathbb{R}^p$ で変換した空間上での距離を当てはまりの関数として用います。
$$ \min_{\alpha \in {\mathbb{R}}^d } \frac{1}{2} || \phi(y) - \Phi \alpha ||^2_2 + \lambda || \alpha ||_1 $$
ここで $\Phi = [\phi(u_1), \cdots, \phi(u_d)] \in \mathbb{R}^{p \times d}$ であり $u_k = [x_{k, 1}, x_{k, 2}, \cdots, x_{k, n}]$ はすべてのデータの第 $d$ 番目の特徴を並べたベクトルです。目的変数 $y$ も $\phi$ を使って変換しているため, データへの当てはまり部分が $p$ 次元上での L2 ノルムになっていることに注意してください。
最適化する重み $\alpha$ は $d$ 次元ですから、回帰係数として捉えることができ、これの大きい物を選ぶことで特徴量選択として用いることができます。
これを解く場合には、双対問題を考えることでカーネルトリックを使うことができます。したがって、内積 $\phi(x)^{\rm T} \phi(y)$ にあたるカーネル関数さえ用意すれば解くことができます。
双対空間上では $d \times d$次元のヘッセ行列の逆行列計算を行なうことになるため、データ $n$ が次元数 $d$ に比べて大きい時に有利な手法です。
FVM は非線形性を扱えてかつ特徴選択にも用いることもできる手法ですがいくつかの欠点も抱えています。
提案されたオリジナル論文では、カーネルとして相互情報量が使われていました。相互情報量をカーネルにもつヘッセ行列は正定値行列と限らず、双対問題は非凸最適化になり、解くことが難しいです。また先にデータ数が大きい時有利とかきましたが、反対に言えば特徴次元数が大きい時には不利になりますし、そのような場合にはヘッセ行列が singular になりやくこれまた解くことが難しいです。
また回帰・分類問題の種類によらずに、目的変数 $y$ を入力 $x$ を同じ非線形関数で変換する必要があるという構造上の欠点も抱えています。
HSIC Lasso
表題にもなっています HSIC Lasso は以下の目的関数を最適化することで、特徴量の重要度を算出します。
$$ \min_{\alpha \in {\mathbb{R}}^d } \frac{1}{2} || \tilde{L} - \sum_{k=1}^d \alpha_k \tilde{K}^k ||^2_{\rm Frob} + \lambda || \alpha ||_1 \\ s.t.\ \alpha_i \ge 0\ (i = 1,2,\cdots d) $$
Frob は行列の要素ごとのノルム(フロベニウスノルム)です。$L$, $K$ はそれぞれ予測値, 特徴量を変換したグラム行列で, $\tilde{L} = \Gamma L \Gamma$, $\tilde{K} = \Gamma K \Gamma$ のように中心化行列 $\Gamma = I_n - \frac{1}{n} 1_n 1_n^{\rm T}$ によって中心化が施されています。
出力 $y$ に対してグラム行列を定義しているので出力に対して非線形性を自然に組み込めていること、さらには入力に対して出力と別のグラム行列を定義していますので、入力の非線形性も捉えることができていそうな感じはしますね。
Note.1 中心化行列 (centering matrix)
中心化行列: https://en.wikipedia.org/wiki/Centering_matrix はいくつかの嬉しい性質を持った行列です。特徴のひとつに「あるベクトル $v$ に対して中心化行列 $\Gamma$ を掛け算するとベクトルの要素の平均値を引く演算になる (結果の平均値がゼロになって""中心化""される)」というものがあります。
$$ \Gamma v = v - \frac{1}{N} 1_N \sum_{n=1}^N v_n = v - \mu $$
ここで $\mu_i = 1/n \sum_{n=1}^N v_n$ で表される値。要するに $v$ の平均値で全部並べたベクトル。
HSIC Lasso を解釈する
提案手法のデータへの当てはまりの第一項を変形すると以下のようになります。
$$ \frac{1}{2} {\rm HSIC} (y, y) - \sum_{k=1}^{d} \alpha_k {\rm HSIC} (u_k, y) + \frac{1}{2} \sum_{k,l=1}^d \alpha_k \alpha_l {\rm HSIC} (u_k, u_l) $$
ここで現れている ${\rm HSIC} (u_k, y) = {\rm tr} (\tilde{K}^{(k)} \tilde{L})$ は Hilbert-Schmidt Independence Criterion (HSIC) と呼ばれるカーネルを用いた2変数間の独立性を測る基準の推定量です。
HSIC の気持ち
HSIC(a, b) は必ずゼロ以上の値をとり、またガウスカーネルのような稠密なカーネル関数 (universal kernel) を使っている場合、2つの変数が統計的に独立なときにゼロになり、その逆もなりたちます (ゼロであることと独立であることは同値)。また2つの変数の動きが連動していると大きな値を取ります。(a側が似ているとb側も似ていて, a側が似ていないときb側も似ていないと大きな値を取る)
やっていることの気持ちとしては「カーネルという類似度が入った空間でふたつの変数をみたとき、それぞれの連動している度合い(依存度合い)」を表している数値、といえます。
NOTE.2: 推定量
当たり前といえば当たり前ですが、先ほど定義した ${\rm HSIC} (u_k, y) = {\rm tr} (\tilde{K}^{(k)} \tilde{L})$ は HSIC の推定量であることに注意してください。実際の HSIC は真の分布がわかっていないと知ることができません。構造としては平均値の推定にデータの平均を使うのと一緒ですね。推定量が上手く機能しない (データが増えてもなかなか収束しないなど) と困りますがある種の収束をすることは保証されています。 *1
あてはまり・再掲
さてこの気持ちを念頭において、 HSIC であらわされた当てはまりの項をもう一度確認してみましょう。第一項は定数 ($y$ は動かないためです) ですからとりさってしまって$\alpha$ に関係する部分のみ再掲します。
$$ - \sum_{k=1}^{d} \alpha_k {\rm HSIC} (u_k, y) + \frac{1}{2} \sum_{k,l=1}^d \alpha_k \alpha_l {\rm HSIC} (u_k, u_l) $$
最初の項は特徴量の $d$ 次元目と目的変数 $y$ とがどれぐらい似通っているかを測っていることがわかります。 全体に負がかかっていますからこの部分を大きくするように、言い換えると $y$ に似ている次元ほど対応する係数 $\alpha_d$ も大きくなります。
また次の項は特徴量 $u, l$ 同士の類似度を見ていることがわかります。 この部分は小さくなるようになりますから、似ている冗長な変数の係数どうしの $\alpha$ は 0 に押しつぶされ、相互に似ていない特徴量の係数が相対的に大きくなることを意味しています。
結果として予測値 $y$ と動きが似ているもののうちで、互いに似ていない特徴量が選択されることになります。
Kernel の選択方法
入力に対してはガウスカーネルを使いますが、出力に対するカーネルは回帰問題と分類問題で使い分けを行っています。これは分類問題においてガウスカーネルを使うことは自然ではないから (実際ガウスカーネルを使った場合性能が悪化する at Figure4 )です。分類問題ではデルタカーネルを使うことが提案されています。
$$ L(y, y') = \begin{cases} 1/n_y\ &{\rm if}\ y= y' \\ 0\ &{\rm otherwise} \end{cases} $$
ここで $n_y$ はラベルが $y$ のデータの数です。これは予測値が特定のクラスになった時だけ値が存在するカーネルで、グラム行列でいえばone-hot へ変換したあとに列ごとに正規化しているような行列と表現できるかもしれません。
別の手法との関係性
論文中ではいくつかの手法が似ているものとして取り上げられていました。ここでは解釈が似ているものとして一番最初に提示されていた mRMR について述べていきます。
Minimum Redundancy Maximum Relevancy (mRMR)
HSIC Lasso を解釈する、のセクションで項毎の意味合いについて考えました。それは minimum redundancy maximum relevancy (mRMR) をベースとした特徴選択のアイディアに近いもので、名前の通り (特徴どうしの)冗長性は小さく・(目的変数との)関連性は大きくなるものが選ばれるような指標になっています。
mRMR は $m$ 個の特徴のみで構成した一部分の行列 $V \in \mathbb{R}^{m \times n }$ から
$$ {\rm mRMR}(V) = \frac{1}{m} \sum_{k=1}^m \widehat{{\rm MI}}(v_k, y) - \frac{1}{m^2} \sum_{k, l=1}^d \widehat{\rm MI}(v_k, v_l) $$
を計算して、この値がもっとも大きくなるような特徴集合 $V$ を選びます。ここで $\widehat{\rm MI}$ は経験相互情報量 (Empirical Mutual Information)*2 で, カーネル密度推定によって得られた確率密度関数 $\hat{p}_{x, y}$ を用いて以下のように計算されます
$$ \widehat{\rm MI}(x, y) = \int \int \hat{p}_{x, y} (x, y) \log \frac{ \hat{p}_{x, y} (x, y)} { \hat{p}_{x} (x) \hat{p}_{y} (y) } dx dy. $$
mRMR の第一項は目的変数と特徴との依存関係を、第二項は特徴量同士の依存関係を表していて、これは HSIC Lasso の解釈部分とにていることが解ると思います。また高速な実装可能な為高次元特徴量でも扱うことが可能です。
しかし mRMR は組み合わせごとに指標を計算しなくてはならない、という欠点があります。これにより、ナイーブにすべての組み合わせに対して計算を実行することは難しいので、貪欲方を使って要素を足したり・引いたりしつつ最適な組み合わせを探すことが実験的には使われますが、得られた解が局所的最適な特量の組み合わせになる可能性があります。*3
また mRMR ではカーネル密度推定によって密度関数を推定していますが、データ数が少ない時密度推定自体の信頼度が低くなり、上手く MI を推定できないことも指摘されています。たしかにそれはそうとう言う感じはします。
実験
3つのシナリオで実験が行われています。
人工データでの比較
まずは人工的に作成されたデータセットです。一つが加法性が成り立つ生成関数 (additive model) から作成された Data1、もうひとつが成り立っていない Data2 です。それぞれ 3 / 4 個の目的変数に関与する有効な変数と同時に、 256 / 1000 次元の無意味な特徴量も同時に加えています。
比較対象のアルゴリズムのなかに加法性を仮定しているもの (SpAM) があるため追加されているのかな?と想像しています。

実験結果は上記のとおりです。(a,b) ではデータの数を増やしていったときに、有効な変数をどのぐらいの割合選べたかを比較しています。これを見ると Data1/2 のどちらの場合も HSIC Lasso とそのバリエーションである NOCCO Lasso が上手く有効な特徴を選べていることがわかります。また (c) では他の手法と計算時間を比較していますがこちらを見ても比較的計算量の増加が緩やかであることがわかります。(d) では特徴量の次元数に応じて計算時間の比較をしていますが、傾きは変わらず大きなデータでも扱えることが見て取れます。
リアルデータでの比較
次に現実のデータ・セットを使って性能を比較します。まずは予測性能から。特徴選択に注目した予測性能の比較のため、実験は以下の3段階になっています。
2で学習する機械学習モデルにはガウスカーネルを用いた Kernel Logistic Regression を利用しています。

Figure2 を見ると画像系タスクでは提案手法が強く、それ以外のデータでも既存手法と同等かそれ以上の性能が発揮できていることがわかります。
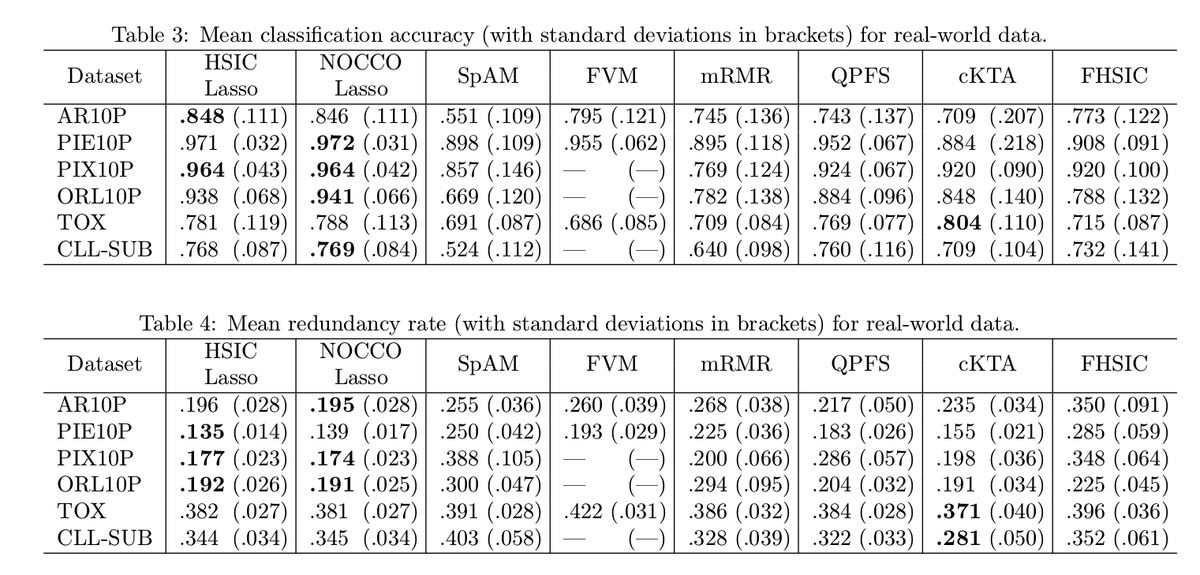
Table4 では冗長性についても比較されています。冗長性は選ばれた特徴量同士の相関係数の平均値のことです。これを見ると提案手法の冗長性が低いことがわかります。比較手法のなかにある cKTA は (特徴選択ではない文脈で) 提案手法のようにグラム行列を使った目的関数を持っていて l1 正則化がないこと・Dualで解くこと以外が同じですので、提案手法は負けていますが HSIC をアルゴリズムのコアに持った手法が有効である、ということは言えそうです。
カーネルの選択での比較
HSIC Lasso はカーネル選択とカーネルを定めるハイパパラメータも問題設定を定めるパラメータの一つです。どのパラメータがセンシティブ、あるいはあまり気にしなくても良いパラメータなのかは気になるところです。
論文中では入力変数のガウスカーネルをスケールと、出力に対するカーネルの選び方 (Delta or Gaussian) で性能比較を行っています。
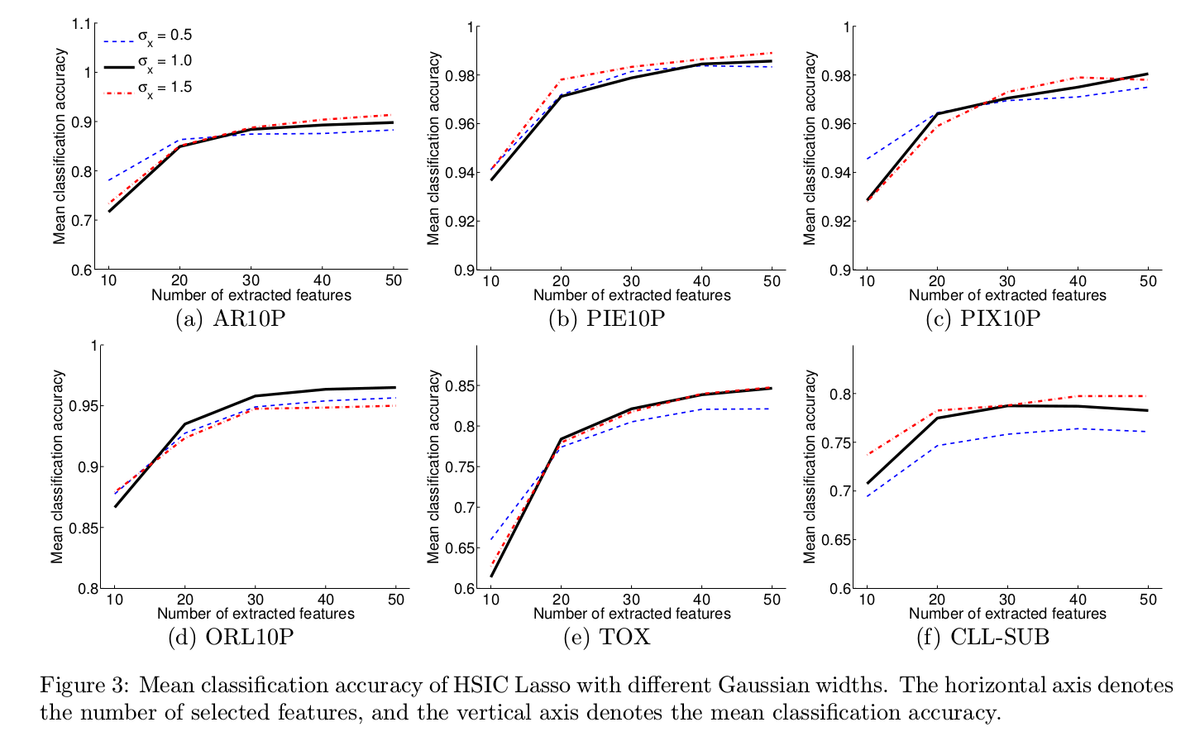
Figure3 は入力に対応するガウスカーネルのスケールごとの性能比較です。これを見るとあまり変化がなく、ガウスカーネルのスケールは大きな影響を与えないことがわかります。

一方、Figure4 では出力のカーネルの種類での性能比較です。こちらを見ると Gaussian のとき大きく性能が悪化していることがわかり、入力出力でカーネルの種類を変えることが有効であることを示しています。また分類問題のラベルに対してガウスカーネルを考えることが不自然、という考えがある種正しいことの裏付けにもなっています。
高次元な問題での比較
最後に特徴量がとても多いデータ (データ数120 / 特徴量 31098) での比較を行っています。このデータはネズミの遺伝子がはいったデータです。タスクとしては特定の遺伝子 TRIM32 に近いものを探すというものです。*4遺伝子情報は実数ですので、解くのは回帰問題です。こちらも結果を見ると他の手法で得られた特徴に比べて良い性能を出していることがわかります。
個人的気になりポイント・感想
- HSIC という基準をはじめて知った。世の中にはいろんな便利な道具があって考える人がいるんだなと改めておもった。
- 上記に関連するが、HSIC の雰囲気がわかってない。あるデータとカーネルがあった時こうなるよ、という値の対応関係とかわかっているとより深く解釈ができて良さそうなので、実験してみたい。
- HSIC Lasso を考えたひとは最初からこの定式化を思いついたのだろうか。最初は mRMR の形から逆算したのかな? (展開形式から L2 っぽく書き直した?) お気持ち気になる木。
- 特徴選択アルゴリズムの比較で、学習させるモデルが線形でなかった場合どうなるのかが気になる。
参考文献
- 変数間の関係を捉えたいあなたへ 統計学勉強会#2 Hidehisa Arai: https://www.slideshare.net/HidehisaArai/2-245213335
- すべての始まり
- High-Dimensional Feature Selection by Feature-Wise Kernelized Lasso: https://arxiv.org/abs/1202.0515
- HSIC Lasso 提案論文。理研の方なんですね
- Measuring Statistical Dependence with Hilbert-Schmidt Norms: https://link.springer.com/chapter/10.1007/11564089_7
- HSIC が提案された論文。HSIC の性質や、この記事で紹介しているHSICの推定量の一致性やデータ数に対する収束速度などの議論ものっています。pdf は http://www.cs.cmu.edu/~arthurg/papers/GreHerSmoBouSch05a.pdf ここから見ることができる。
- Learning Co-Substructures by Kernel Dependence Maximization https://bigdata.nii.ac.jp/eratokansyasai4/wp-content/uploads/2017/09/efde2feefebb2002101b897fd1234aca.pdf
- HSICの説明が一部載っている。
- ノンパラメトリック推論への展開 正定値カーネルによるデータ解析 - カーネル法の基礎と展開 -: https://www.ism.ac.jp/~fukumizu/ISM_lecture_2010/Kernel_6_nonparam.pdf
- 福水先生の資料。RKHS上で平均・分散・依存関係を考えるとは?について端的にまとまっていてわかりやすいです。
- Minimum redundancy feature selection from microarray gene expression data: https://pubmed.ncbi.nlm.nih.gov/15852500/
- mRMR の提案論文. pdf は http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.62.6875&rep=rep1&type=pdf ここから見れます。
*1:Measuring Statistical Dependence with Hilbert-Schmidt Norms Section3・4参照
*2:相互情報量は、変数Aの値を知った時に変数Bの不確実性がどのぐらい減るかを表したものと解釈することができる。モデルの予測の不確実性を調べる 敵対的サンプリング検出のための基準としての相互情報量 - Understanding Measures of Uncertainty for Adversarial Example Detection - nykergoto’s blog 見たいな文脈でも出てきたりする
*3:[memo]: HSIC Lasso は一度問題を解くと自然に特徴の重要度が得られますので、この点では HSIC が優っていると言えそう。
*4:ちょっと気になって元のデータにアクセスしてみたかったのですがオンラインで見られるところにはなさそうでした。残念。
pythonで実行時間を測定しつつ時間も取得したい
実行時間を測定するには?
KaggleMasterのアライさん著・Kaggleコード遺産でおなじみ timer を使うのが便利です! いつもお世話になってます😊
from contextlib import contextmanager from time import time # https://qiita.com/kaggle_master-arai-san/items/d59b2fb7142ec7e270a5#timer をちょっといじったやつ @contextmanager def timer(logger=None, format_str='{:.3f}[s]', prefix=None, suffix=None): if prefix: format_str = str(prefix) + format_str if suffix: format_str = format_str + str(suffix) start = time() yield d = time() - start out_str = format_str.format(d) if logger: logger.info(out_str) else: print(out_str)
あとは、測りたいコードの部分を with 区でくくります。かんたんで便利ですね!
with timer(prefix='foo'): # run some function sleep(10)
しかし timer は print で時間を表示してくれるものの時間の計測が timer 側で閉じてしまっているので、計測後に実行時間を取得することができません。たとえば実行時間を console に出しつつデータフレームなどに保存したい〜というときなど、実行時間自体にアクセスしたいですね。
Classを使って書き直す
これを解決する一つの方法が timer 自体に時間などを保存できるようにする方法です。timer ごとに値を属性として保存するため funcition だったものを Timer class に書き直しました
class Timer: def __init__(self, logger=None, format_str='{:.3f}[s]', prefix=None, suffix=None, sep=' '): if prefix: format_str = str(prefix) + sep + format_str if suffix: format_str = format_str + sep + str(suffix) self.format_str = format_str self.logger = logger self.start = None self.end = None @property def duration(self): if self.end is None: return 0 return self.end - self.start def __enter__(self): self.start = time() def __exit__(self, exc_type, exc_val, exc_tb): self.end = time() out_str = self.format_str.format(self.duration) if self.logger: self.logger.info(out_str) else: print(out_str)
enter / exit を定義して with のときの動作を書いているだけです。
これを使うと一度定義した timer に start_at / duration などの属性がひも付きますのであとから時間を取り出すことが可能です。
hoge_timer = Timer() with hoge_timer: sleep(10) print(hoge_timer.duration)
また今まで通り timer として使いたいよ〜というニーズもあると思います。その場合以下のように function を定義しておけば OK です
def timer(logger=None, format_str='{:.3f}[s]', prefix=None, suffix=None, sep=' '): return Timer(logger=logger, format_str=format_str, prefix=prefix, suffix=suffix, sep=sep)
scikit-learn の grid-search を sample_weight と同時に使用する場合の問題点
以下の記事によると scikit-learn の BaseSearchCV の実装には問題があり意図しない動作をしている可能性がある、とのことが報告されています。いつも scikit learn を使う身としては気になる話題なので、少し詳しく見ていきます。
BaseSearchCVと sample weight の問題点
記事中で指摘されている問題点をまとめると以下のようになります。
BaseSearchCVを継承した CV class において, 各 CV ごとの学習自体はsample_weightが適用される- しかし validation set に対する score の計算では
sample_weightが適用されない- 具体的には https://github.com/scikit-learn/scikit-learn/blob/0.24.0/sklearn/model_selection/_validation.py#L620 このあたり
- 例えば pos / negative にそれぞれ 1 / 1000 の重みを与えると本来的の重み付きスコアは 0.999 になっていてほしい。
- だが実際には重みが適用されないので 0.5 のままになる。
検証
試しにさっくり手元の環境でもやってみました。使用するバージョンは最新の scikit-learn==0.24.0 です。
cv = np.array([0, 0, 1, 1]) X = np.ones(shape=(4, 1)) y = np.array([1, 0, 1, 0]) fold = np.array([ [[0, 1], [2, 3]], [[2, 3], [0, 1]], ]) # negative に対して weight を 999 / 1000 で与える sample_weight_for_zeros = [ 1, 999, 1, 999 ] # grid search で学習. 入力が const の linear model なので positive の割合が weight になるはず. grid = GridSearchCV( estimator=LogisticRegression(), param_grid={ 'random_state': [42] }, scoring='accuracy', cv=fold, return_train_score=True ) grid.fit(X, y, sample_weight=sample_weight_for_zeros)
上記の設定だと sample_weight は negative に多く設定されています。したがって重み付きのスコアは 0.999 になっていてほしいです。
scikit-learn に実装されている accuracy では sample_weight arg が用意されていて、手動で計算すると以下のようになります.
from sklearn.metrics import accuracy_score # 本当は 0.999 になってほしい accuracy_score(y, grid.predict(X), sample_weight=sample_weight_for_zeros) # 0.999
しかし実際には 0.5 になっています
# 実際には weight がないときと同じスコアになる grid.best_score_ # 0.5
sample_weight が適用されていないのは validation でのスコア計算の部分で, 学習自体は意図した動作です.
# 予測値は negative が 0.999 が出力される (学習自体には sample_weight が適用されているため.) grid.predict_proba(X) array([[0.99900002, 0.00099998], [0.99900002, 0.00099998], [0.99900002, 0.00099998], [0.99900002, 0.00099998]])
まとめ
- 学習自体は sample_weight つきで期待通り実行されるが, 算出される score は sample_weight を無視して計算されている.
- GridSearchCV や RandomSaerchCV など, BaseSearchCV を継承したパラメータサーチでは score の意味で最も良いパラメータが選ばれる.
- したがって, sample_weight を考慮して最も良い parameter が知りたい場合でも, sample_weight を無視したスコアの意味でもっとも良いモデルが選ばれるため、問題.
sample_weight を使っていてかつ sciki-learn の枠組み上でパラメータ最適化を行う場合には注意したほうが良いかもしれません。
以下使用したコードです。