連続変数で StratifiedKFold
pandas.qcut で int に変換すると良さげ
from sklearn.model_selection import StratifiedKFold import pandas as pd def get_stratified_fold_split(X, y, n_folds=10, q=20): # Categorical.codes で各クラスに対応する int が取得できる y_cat = pd.qcut(y, q=q).codes fold = StratifiedKFold(n_splits=n_folds, random_state=71) return fold.split(X, y_cat)
q は int 化するときの分割数なので n_folds に合わせていい感じに合わせると良いかな?
RAdam: Adam の学習係数の分散を考えたOptimizerの論文紹介
表題の通り噂の最適化手法 RAdam の論文 On the Variance of the Adaptive Learning Rate and Beyond を読んだので, そのまとめです!!
概要
一言でいうと「今までヒューリスティックに行っていた Adam 学習開始時の LR 調整を自動化できるような枠組みをつくったよ」ということになると思います.
考える問題
この論文で, 考えていくのは機械学習のように多数のデータから成る目的関数を最小化するような問題です. 特にニューラルネットワークの学習では勾配法, 特に SGD (確率的勾配降下法) と呼ばれる方法を用いることが一般的です.
SGD には様々な adaptive バリエーションがあります.この adaptive とは問題の特性を生かして, SGD を早くするような工夫を指しています.
一般的な形式
一般的な adaptive と呼ばれる SGD は, 方向を決める $\phi$ とそれを補正する係数である $\psi$ を用いて記述することができます.
例えば adam の場合は勾配には勾配の指数加重平均を, 補正係数には勾配の要素ごとの二乗の指数加重平均を用います.
具体的に書き下すと第 $t$ ステップでの更新は, $t$ ステップで得られたサンプルに対する勾配 $g_t$ から
$$ m_t = \frac{(1 - \beta_1) \sum_{i=1}^t \beta_1^{t-i} g_i}{1 - \beta_1^t} \\ V_t = \frac{(1 - \beta_2) \sum_{i=1}^t \beta_2^{t-i} g_i^2}{1 - \beta_2^t} $$
とおいたときに更新したいパラメータ $x_t$ を
$$ x_{t+1} = x_t - \alpha_t \frac{1}{\sqrt{V_t}}m_t $$
として更新を行っていきます. ここで $\beta_1, \beta_2 \in [0, 1]$ は勾配/補正係数の指数加重平均のハイパーパラメータで $\alpha_t \in {\mathbb R}$ は学習係数 (Learning Rate) です。 また $g_i^2$ は成分ごとの二乗を表しています. 即ち $(g_i^2)_j = (g_i)_j^2$ です.
このあたりは僕のスライドになってしまいますが https://speakerdeck.com/nyk510/que-lu-de-gou-pei-fa-falsehanasi?slide=7 あたりを見て雰囲気を掴んでいただけると, あとの話がスムーズに進むかなと思います.
この論文では主に $V_t$ について取り扱いますが, ルートをとって逆数を撮った形式を標準形 $\psi$ として扱います.すなわち
$$ \psi_t = \frac{1}{\sqrt{V_t}} = \sqrt{\frac{1 - \beta_2^t}{(1 - \beta_2) \sum_{i=1}^t \beta_2^{t-i} g_i^2}} $$
を以下では扱います.
SGD の warm start
SGD では学習の初期に小さな LR を使って更新を行い, ある一定のステップが立ったのちに通常の LR を使って SGD を使う, という戦略が取られることがあります. これを warm start といい, adam やその他の adaptive な学習法でも有効であることが確認されています.
warm start が有効な理由
ではなぜ warm start が有効なのでしょうか. 例として Adam でステップ $t=1$ の時を考えてみます.その時補正係数は
$$ \psi_1 = \sqrt{\frac{1}{g_t^2}} $$
となります.このとき仮定として勾配 $g_t$ が正規分布 $N(0,\sigma^2)$ から生成されているとすると $\frac{1}{g_t^2}$ は $\sigma^2$ でスケール化された自由度1のカイ二乗分布の逆数となります.(これを論文中では Scale-inv-$\chi^2 (1, \frac{1}{\sigma^2})$ と表記しています)
このとき $\psi$ の分散は
$$ Var[\psi] \propto \int_{0}^{\infty} x e^{-x} dx = \infty $$
となり発散します.この例で見たようにステップ $t$ が小さいときには補正項の分散は bound されません. したがって補正係数がとても大きい値を取る場合があり挙動が不安定になってしまいます.
論文中でも Figure2 で初期の step の更新で重みの分布が崩壊して学習が上手く進まなくなってしまう様子が可視化されています。
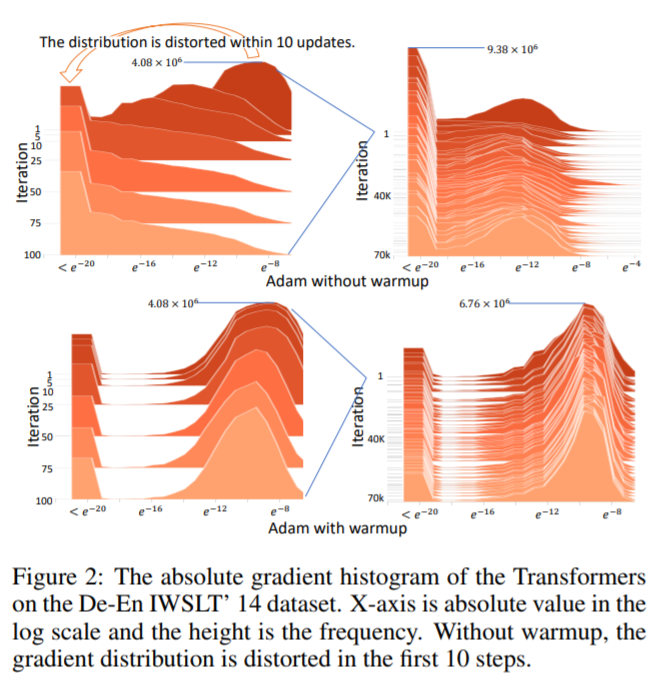
このような不安定性を抱えているため何らかの手段を講じる必要がありますが、その一つの手段が warm start です. warm start では $t$ が小さい領域では lr を小さくするため, 補正係数で bound されない分の上限を lr が変わりに行ってくれます.
このため安定した学習が可能になります. またステップが増えていくと $\psi$ の分散は bound されてくるので lr での bound は初期のステップの範囲だけでOKなこともわかります.
Adam の補正係数の分散
step $t$ が小さい時を考えます.このとき指数加重平均を行う際の重みの差分は $1-\beta_2^t$ 以内に収まります. $\beta_2$ は普通 0.99 程度なので $t$ が小さいときに差分が小さいことがわかります. このことから初期ステップでの指数加重平均は, おおよそ過去の勾配の平均をとったので問題がない, ということがわかります.すなわち
$$ \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} g_i^2}{1-\beta_2^t} \sim \frac{\sum_{i=1}^t g_i^2 }{t} $$
とみなせます.これを $\psi$ に当てはめると自由度 $t$ の Scaled inverse $\chi^2 (t, 1/\sigma^2)$ となります.
ではこの分布に従う $\psi$ の分散はどの様になるでしょうか? これを述べているのが Theorem.1 で結論を言うと 自由度を $\rho$ としたとき $\rho$ が増えるに従って分散は単調減少します. (正確には任意の $\rho > 4$ に対して上記が成立します)
これによってステップが増えていけば分散は縮小することがある程度保証されました. ではこの $\rho$ をどのように推定するのか? が次の話題になります.
自由度 $\rho$ の推定
$\rho$ を推定する際に使うのが Simple Moving Average (SMA) という考え方です.これは直近の $f(t,\beta_2) \in {\mathbb N}$ のステップで指数平滑移動平均を近似する, というものです.すなわち
$$ p\left( \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} g_i^2}{1-\beta_2^t} \right) \sim p \left( \frac{\sum_{i=1}^{f(t,\beta_2)} g_i^2 }{f(t,\beta_2)} \right) $$
を満たす, ということです.これを先の議論と合わせて考えると自由度 $\rho$ は $f(t,\beta_2)$ とみなせます.
この $g_i$ に対して $g_i = (t + 1 -i)$ であっても成り立ってほしい!ということで単に代入してやると
$$ p \left( \frac{(1-\beta_2)\sum_{i=1}^t\beta_{2}^{t-i} (t + 1 -i)}{1-\beta_2^t} \right) \sim p \left( \frac{\sum_{i=1}^{f(t,\beta_2)} (t + 1 -i) }{f(t,\beta_2)} \right) $$
を満たしている必要があるということになります. これを解くと*1
$$ f(t, \beta_2) = \frac{2}{1-\beta_2} - 1 - \frac{2t\beta_2^t}{1 - \beta_2^t} $$
を得ます.これを見ると $t \to \infty$ のとき $\rho_{t} \to \frac{2}{1 - \beta_2} - 1$ であることがわかります.(この値を $\rho_{\infty}$ とおきましょう) また $ \frac{2t\beta_2^t}{1 - \beta_2} > 0$ であることを考慮すると, $\rho_t < \rho_{\infty}$ であることもわかります.
$\psi$ の分散推定
では次に $\psi$ の分散がどの様になるのか考えていきます. 煩雑になるので飛ばしましたが Theorem.1 で分散を厳密に計算することができ, そのオーダーは $Var[\psi] = O(\frac{1}{\rho_t})$ であることがわかっています.(単に式変形するだけです) これと Theorem.1 の主張である「$\rho$ が大きいとき分散は小さい」を組み合わせると, 分散の最小値は $t \to \infty$ のとき, すなわち
$$ \min_{\rho_t} Var[\psi] = Var[\psi] |_{\rho_t = \rho_\infty} $$
であることがわかります(この最小値を $C_{var}$ とおきます.). すなわち $\rho_\infty$は計算可能ですから分散の最小値は見積もれる, ということです.
ここで, 学習が進むにつれて補正係数 $\psi$ のオーダーは変化しないことが望ましいことを思い出してください. これは補正係数が変わってしまうと, 最適な LR の値もかわってしまうためです.
したがって各ステップでの補正係数は, $C_{var}$ 程度の大きさになるようになってほしい, ということです. すなわちもともとの adam などの補正係数 $\psi_t$ に対して修正用の係数を $r_t \in {\mathbb R}$ かけて
$$ Var[r_t \psi] = C_{var} $$
が満たされていてほしいです.すなわち
$$ r_t = \sqrt{\frac{C_{var}}{Var[\psi]}} $$
を満たすように $r_t$ を選べば良いことがわかります. ではあとは計算するだけ, ですがこの係数を見積もるためには $Var[\psi]$ を知っている必要があります. これは解析的に計算することが困難なので ${\mathbb E}[\psi^2]$ の周りで Taylor 展開をした一次の部分を使ってやると
$$ Var[\psi] \sim \frac{\rho_t}{2(\rho_t - 2)(\rho_t - 4)\sigma^2} $$
を得ることができます.これと $\rho > 4$ のとき $Var[\psi]$ が単調減少であることを考慮すると $\rho > 4$ の範囲において
$$ r_t = \sqrt{\frac{(\rho_t - 4)(\rho_t - 2) \rho_\infty}{(\rho_\infty - 4)(\rho_\infty - 2) \rho_t}} $$
を設定することが良いことがわかります.
以上を記述したのが Algorithm.2 になっています.

はじめ各ステップで $\rho_t$ を計算します.この $\rho_t$ が大きいときは $Var[\psi]$ が小さいことを示していますから, Adam のような補正をかけることが正当です. 具体的には $\rho > 4$ の条件に合うかどうかを調べて当てはまった場合上記の補正を入れた勾配+補正項で更新します.
そうでない $Var[\psi]$ が大きいときには更新が十分に行われていないと判断して補正項を使わずに勾配のみを使って momentum で更新を行います.
ここで $\beta_2$ が小さいとき、具体的には0.6以下のときには $\rho_t $ がつねに4以下になる、ということに注意してください。
要するに $\beta_2$ があまりに小さすぎると $Var[\psi]$ は常に大きな値を取り続けると想定されるため Adam のような adaptive な更新を行うことは不適切 と判断される、ということです。この場合ずっと momentum のみの更新が行われます.
実験と考察
はじめに pure な Adam と SGD との比較を行っています.

この結果を見ると pure Adam にはどちらの条件でも勝っていることがわかります. *2
上記の実験は最も良いものを tuning した結果でしたが実際に実験する際にはどのようなパラメータでも学習がうまく進むことが望ましいですよね. それを調べるべくいちばん大事なパラメータ LR に対して学習がどのように変化するかが次のグラフです.
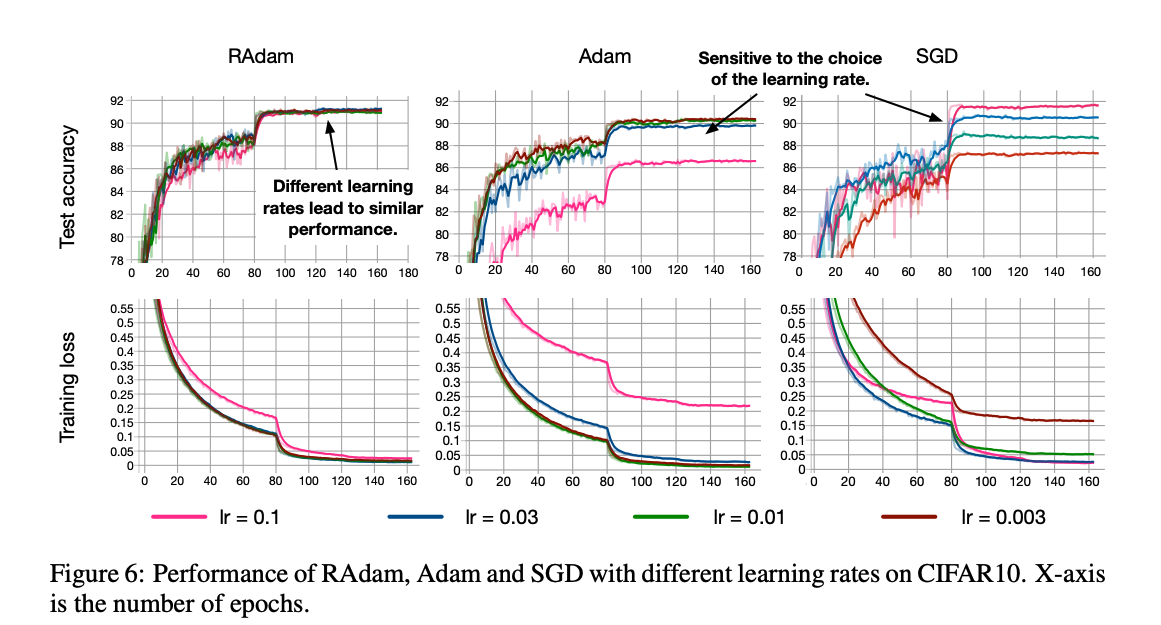
これを見ると RAdam がどのパラメータに対しても学習がうまく進んでいることが一目瞭然です.
次の実験はヒューリスティックな warm start と RAdam の戦略の差分を見るための実験です.
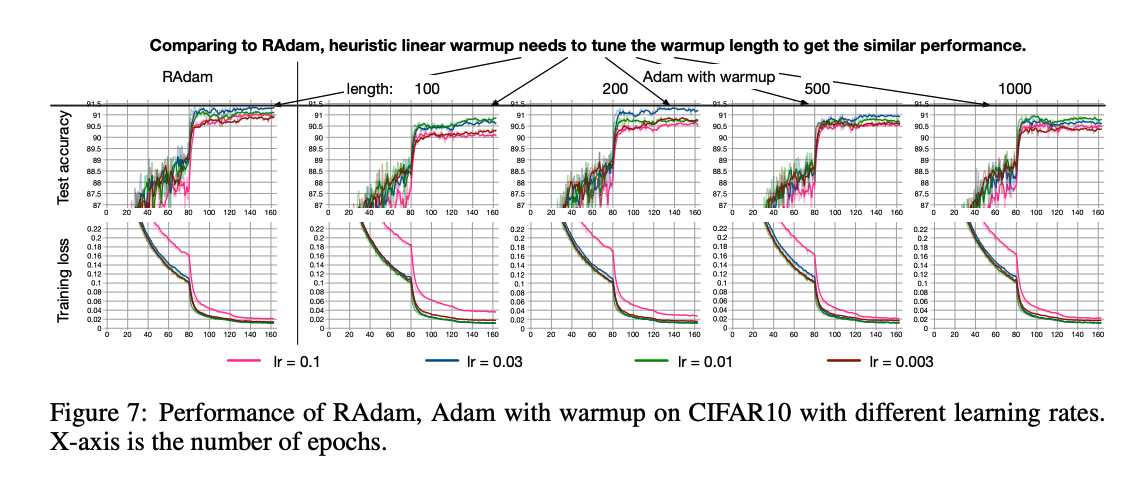
RAdam はいい感じに warm start をする方法, と捉えられますから RAdam が有効に働いていることが見て取れます.
他にも論文中での近似がうまくいっているかどうかの実験なども乗っています, が力尽きました.
結論と感想
Adam など adaptive な手法と同時に使われる warm start をうまく最適化のフローに取り込んだ RAdam という手法を紹介しました. 結果を見る限り warm start は必要ないような結果となっており, 職人芸的な LR 設定がひとつなくなって幸せなのかなと思いました.
また本論と関係ありませんが, この論文自体は microsoft のインターンの方が書かれたようでインターンでこれするんかというレベルの高さを感じました.
個人的な感想として以前紹介した Adabound が全く流行っていないのでこっちは流行ってほしいかなーと思いました.(warm start というヒューリスティックな方法をリプレイスできるというのは Adabound のSGDとの連続的な接続よりもインパクトがあるとも思いますので.)
参考文献
機械学習のための環境構築とその管理
機械学習プロジェクトでは python を始めとした言語 + それに付随したライブラリを使います。 僕も python 触りたての頃はローカルマシン上にひとつ python 環境を作り、必要なライブラリをインストールして使っていました。環境の分離ということはあまり意識しておらず、やったとしてもプロジェクトごとに anaconda や pyenv, venv などで個別環境を作って切り分けるレベルでした。
しかし上記の方法だと困ったことが起ることがあります。例えば…
- global な環境が壊れてしまってすべて壊れる。
- linux / Mac / Windows で互換性がない
- これまた上記と近いですがパソコン自体を変えた時に環境が持ち運べないのが原因です。
requirements.txtだけ共有すればいいと思っていた時代が僕にもありました。
- システム化するときにひと悶着ある
- ローカルマシンとサーバーの環境は一般に異なるので推論サーバーをAPIとしてデプロイしたい、という時にさっくり行かない場合があります。
Docker の登場

そこで有望なツールが Docker です。 Docker はコンテナベースの仮想環境ツールです。一般の仮想環境ツール同様にどのOSで動かすかは選べますし、アプリケーション単位での仮想化が可能で実行はとても高速です。
弊社でのシステム開発では Docker を使わない、ということは殆ど無いと言ってもいいと思う程度には web 開発に置いてスタンダードとなった技術です。
じゃあ機械学習も Docker で環境作ればいいじゃない!となります。実際僕もプロジェクトごとに Dockerfile を作って build し docker-compose で jupyter を立ち上げる、という運用を行っていました。これによって昔は頻繁にあった Mecab install challenge など不毛な時間は大分減らすことが出来ました。
上記運用の欠点
と言ったものの上記の運用にも欠点があります。大きく言って
- プロジェクト開始時にコピペをする必要がある
- build のコストが高い
- Dockerfile のコピーは Image のコピーを意味しない
という3つの問題があると思っています。
1. プロジェクト開始時にコピペをする必要がある
プロジェクトごとに Dockerfile を書くと書きましたが、大概の場合において基本的に使うライブラリや設定は同じです。たとえば僕の場合であればどのプロジェクトであっても jupyter notebook numpy matploblib seaborn などは必須ですし、グラフの日本語化や日本語フォント NOTO のインストールなどは必ず行います。
毎回覚えていられないので、新規のプロジェクトを作るときには以前の適当なプロジェクトのディレクトリに行って Dockerfile をコピペする作業になります。 この作業はそもそも無駄が多いですし「このプロジェクトでいじった部分がぱっと見てはわからない」というのはもっと深刻です。
めちゃくちゃ似ているけれど微妙に違う dockerfile が沢山出来ることを想定してみて下さい…
共通部分のコードのブラッシュアップも起こりにくい条件なので、あるプロジェクトで A という処理を a というとてもかしこい方法で解決できたとしても、その知識をためていくことが難しい状態です。
2. Build のコストが高い
都度 Image を build するので時間がかかります。単純ですがマシンスペックが限られている環境だと痛い時があります。 特に機械学習だと build に時間がかかるツールもあり他の作業の妨げにもなる場合が多いからです。
過去にその PC で build をしたことがあれば docker が賢くキャッシュを使ってくれるのでその限りではありませんが, RUNの根底から変更するとキャッシュは使えませんし、新しいPCで環境を作ろうとなると必ず build する必要があります。
3. Dockerfile のコピー ≠ Image のコピー
コピペすると厳密に一致する Image が出来るか、というと実はそうではありません。 Image の version やリポジトリの最新状況, python の各ライブラリに至るまで厳密に指定してない限り, Build するたびに完全に一致するものが出来るとは限らないからです。 即ち, Image を決定する要因は Dockerfile + それを実行したタイミングとなるからです。
上記のズレはほとんどの場合において一致するのでまあ問題がないのですが、まれにずれによって Build がコケる場合があります。(例えば最近だと jupyter 内部で使っているあるライブラリの update によって依存がこわれて jupter が起動しないという状態が発生していました)。
各プロジェクトに固有のライブラリ部分はずれていたとしても、共通の部分に関しては完全に一致した状態を作りたいです。
kaggle Image ではあかんの?
上記を解決する手段として例えば kaggle の kernel で使われている Image https://github.com/Kaggle/docker-python/blob/master/Dockerfile を使うという方法があります。こちらは有望ではある一方で日本語周りの対応に一抹の不安があります。それこそ mecab はデフォルトでは入っていませんので自分でインストールする必要があります。
またフォントなども設定する必要がありやはりどうしても共通のコードが発生してしまう為, 上記の問題は同様に起こります。
やりたいこと
結局やりたいのは以下のような事柄です。
- 共通部分はプロジェクトで共有し、できればその部分をみんなで使いまわしたい。
- 共通部分に build のタイミングごとで version をつけて, 厳密に一致することを確保したい。
これを僕は Gitlab CI による自動 build + Gitlab Registry での version 管理でやっていて、割合に便利なので以下で紹介したいと思います。
CI での Build + Registry で version 管理
今回以下で紹介するのは最近僕がやっている Gitlab CI + Gitlab Registry での Image Versioning についてです。
Gitlab CI / Registry とは
まず Gitlab は github と同じ git の管理ツールです。 github よりも無料の範囲で使えることが多くて CI や Registry (Docker Image を保存する機能) も無料でつかうことができます。 CI には実行時間の上限がありますが自分のローカルマシンのリソースをつかって代わりに実行する(!)という方法を取れば実質無限にCIを使えますし, registry は容量制限はありません。
CI / Registry をおくためのプロジェクトの用意
はじめに共通部分を管理するためのリポジトリを用意します。僕のリポジトリは https://gitlab.com/nyker510/analysis-template に作成しています。
そしてこのリポジトリに dockerfile 及び必要なファイル群を tracking していきます。
例えば cpu version の dockerfile https://gitlab.com/nyker510/analysis-template/blob/master/docker/cpu.Dockerfile の最新状態は以下のようになっています。
FROM ubuntu:16.04
ARG JUPYTER_PASSWORD="dolphin"
ARG USER_NAME="penguin"
ARG USER_PASSWORD="highway"
ENV LANG=C.UTF-8 LC_ALL=C.UTF-8
# Install dependences
RUN apt-get update --fix-missing && \
apt-get install -y \
wget \
bzip2 \
ca-certificates \
libglib2.0-0 \
libxext6 \
libsm6 \
libxrender1 \
git \
mercurial \
subversion \
sudo \
git \
zsh \
openssh-server \
wget \
gcc \
g++ \
libatlas-base-dev \
libboost-dev \
libboost-system-dev \
libboost-filesystem-dev \
curl \
make \
unzip \
vim \
# MeCab
swig mecab libmecab-dev mecab-ipadic-utf8 \
cmake --fix-missing
ENV TINI_VERSION v0.6.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /usr/bin/tini
RUN chmod +x /usr/bin/tini
ENTRYPOINT ["/usr/bin/tini", "--"]
# Install miniconda dir and add path
ENV CONDA_DIR /opt/conda
ENV PATH ${CONDA_DIR}/bin:${PATH}
RUN wget --quiet https://repo.continuum.io/miniconda/Miniconda3-4.5.12-Linux-x86_64.sh -O ~/miniconda.sh && \
/bin/bash ~/miniconda.sh -b -p ${CONDA_DIR} && \
rm ~/miniconda.sh
RUN conda install -y conda
RUN conda install -y \
numpy \
scipy \
scikit-learn \
jupyter \
notebook \
ipython
RUN conda install -c conda-forge lightgbm xgboost
# Add $CONDA_DIR/bin to sudo secure_path
RUN sed -r "s#Defaults\s+secure_path=\"([^\"]+)\"#Defaults secure_path=\"\1:$CONDA_DIR/bin\"#" /etc/sudoers | grep secure_path > /etc/sudoers.d/path
## install lightGBM
#RUN git clone --recursive https://github.com/Microsoft/LightGBM && \
# cd LightGBM/python-package &&\
# python setup.py install
# install note fonts
# use apt-get install note-fonts, matplotlib can't catch these fonts
# so install from source zip file
# see: http://mirai-tec.hatenablog.com/entry/2018/04/17/004343
ENV NOTO_DIR /usr/share/fonts/opentype/notosans
RUN mkdir -p ${NOTO_DIR} &&\
wget -q https://noto-website-2.storage.googleapis.com/pkgs/NotoSansCJKjp-hinted.zip -O noto.zip &&\
unzip ./noto.zip -d ${NOTO_DIR}/ &&\
chmod a+r ${NOTO_DIR}/NotoSans* &&\
rm ./noto.zip
# install additional packages
ADD docker/requirements.txt requirements.txt
RUN pip install -U pip && pip install -r requirements.txt
# remove cache files
RUN apt-get autoremove -y && apt-get clean && \
conda clean -i -l -t -y && \
rm -rf /usr/local/src/*
# enable jupyter extentions
RUN jupyter contrib nbextension install
# user をルートユーザーから切り替えます
# ユーザー名とパスワードは arg を使って切り替えることが出来ます (このファイルの先頭を参照)
RUN groupadd -g 1000 developer &&\
useradd -g developer -G sudo -m -s /bin/bash ${USER_NAME} &&\
echo "${USER_NAME}:${USER_PASSWORD}" | chpasswd
USER ${USER_NAME}
# jupyter の config ファイルの作成
RUN mkdir ~/.jupyter &&\
echo "c.NotebookApp.open_browser = False\n\
c.NotebookApp.ip = '*'\n\
c.NotebookApp.token = '${JUPYTER_PASSWORD}'" | tee -a ${HOME}/.jupyter/jupyter_notebook_config.py
ADD docker/jupyter-custom.css /home/${USER_NAME}/.jupyter/custom/custom.css
ADD docker/matplotlibrc ${CONDA_DIR}/lib/python3.7/site-packages/matplotlib/mpl-data/matplotlibrc
ADD docker/ipython_config.py ${HOME}/.ipython/profile_default/
# vim key bind
# Create required directory in case (optional)
RUN mkdir -p $(jupyter --data-dir)/nbextensions && \
cd $(jupyter --data-dir)/nbextensions && \
git clone https://github.com/lambdalisue/jupyter-vim-binding vim_binding
WORKDIR /code/
EXPOSE 8888
CMD [ "jupyter", "notebook", "--ip=0.0.0.0", "--port=8888"]
内部では matploblibrc や jupyter の css, NOTO Font のインストールと設定などの情報も設定する用になっていてそれらのファイルもこのリポジトリの監視対象としています。 これによって jupyter で日本語が豆腐化したりすることを防げます。
また root 権限のないユーザーで実行するように記述されていますので外部公開するような API を作る際にも安心です。
Gitlab CI の設定
上記が完了したら .gitlab-ci.yml で master merge 時に以下を実行するように記述していきます。
- この dockerfile を使ってイメージの作成
- CI が動いたタイミングにユニークに書きだされる hash をタグとしてつけて gitlab-registry に push
このリポジトリでは cpu 用の dockerfile と gpu 用の dockerfile を同時に管理しています。それらの build には共通のコードが多く存在しますので gitlab-ci にある include 及び extend を使って共通部分のコードをまとめて管理する用になっています。
以下は特定の dockerfile を build して push するための基底クラス .build-dockerfile です。
# build dockerfile and push to registry
# default registry is set gitlab-registry.
#
# @arguments
# @IMAGE_NAME: built image name.
# @DOCKEFILE: path to dockerfile.
.build-dockerfile:
stage: build
script:
- echo ${REGISTRY_URL}
- export TAG=${REGISTRY_URL}/${IMAGE_NAME}
- docker build -t ${TAG}:latest -f ${DOCKERFILE} ${CONTEXT}
- docker tag ${TAG}:latest ${TAG}:${CI_COMMIT_SHA}
- docker push ${TAG}:latest
- docker push ${TAG}:${CI_COMMIT_SHA}
variables:
IMAGE_NAME:
DOCKERFILE:
# if you use own values, override in variables scope.
CONTEXT: .
# ex.) registry.gitlab.com/atma_inc/analysis-template
REGISTRY_URL: ${CI_REGISTRY}/${CI_PROJECT_NAMESPACE}/${CI_PROJECT_NAME}
実際に使う際には以下のように IMAGE_NAME, DOCKEFILE を指定します。
例えば cpu version だとパスは ./docker/cpu.Dockerfile で名前は cpu にしたいので以下のようになります。
image: docker:git
services:
- docker:dind
include:
- local: 'templates/.build-dockerfile.yml'
.build-basic-docker:
extends: .build-dockerfile
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
stages:
- build
build-cpu:
extends: .build-basic-docker
variables:
IMAGE_NAME: cpu
DOCKERFILE: ./docker/cpu.Dockerfile
実際にはもうちょっと設定が入っているので上記の build は master merge 及び merge request が起こったタイミングで実行される用になっています。
詳しくは document https://docs.gitlab.com/ee/ci/yaml/README.html のほう参照していただければと思いますが、本当に多種多様な制御の方法がありこれを使いこなせるだけで相当の価値があると思います。(僕はまだ全然使えていません)
運用方法
たとえば特定のライブラリが共通部分としてほしいなーと思ったとしましょう。そうすると以下のようなフローで master の更新及び Image の version 作成が行われます。
- 適当に merge request を送る
- 送った段階で build が自動的に動き OK だったら merge
- merge された段階で再度 build して, gitlab-registry 上に tag 付きで push。

この時必ず新しい tag 名でも push するので, latest は更新されますが古い Image は上書きされません。
これによって最新の master は <IMAGE_NAME>:latest という名前で参照できかつ過去の状態も tag を指定すれば参照することが出来ます。
例えば今の僕の Image は以下のようになっていてこの運用を始めた3ヶ月前からの version ができていることがわかります。

この方法だと build が失敗した, すなわち共用の Image に何らかの問題が発生している場合でも過去の Image 自体は残っていますので、そちらを参照すれば一応分析業務は行うことが出来ます。その間にいい感じに直して, 再度 merge ということをやれば良いのでプロジェクト開始時に慌てふためく、ということは先ずありません。
新規プロジェクトの時の始め方
上記がある前提であたらしいプロジェクトをはじめてみましょう。
まずは共通部分ですべて事足りる場合から。この時は新規プロジェクトでは Dockerfile を書く必要はありません。 単に Image を gitlab registry にある特定の version のものを選択するだけです。
このとき docker-compose.yml を使うと volume のマウントや環境変数の設定が楽で良いです。例えばですが本当の最小単位だと以下のようになると思います。
version: "2.3"
services:
jupyter:
# latest でなく特定の hash を指定すれば厳密に環境を揃えることができる
image: registry.gitlab.com/nyker510/analysis-template-cpu:latest
container_name: my-awesome-app
ports:
- 8888:8888
これだけでいつも使うライブラリ全部いりの jupyter が立ち上がります。楽ちんですね。
一点だけ gitlab registry を Docker に認識してもらうためにログインだけ行えば後は docker-compose pull で該当するイメージを pull してから up するだけです。
docker login registry.gitlab.com Authenticating with existing credentials... WARNING! Your password will be stored unencrypted in /home/nyker-goto/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded docker-compose pull docker-compose up -d
実際は volume とか python path などを設定すると便利なのでそれらをすべて定義した docker-compose.common.yml などを以下のように作って
# docker-compose.common.yml
version: "2.3"
services:
jupyter:
build:
context: ./
dockerfile: ./docker/${CONTEXT}.Dockerfile
image: registry.gitlab.com/nyker510/analysis-template-cpu:latest
container_name: ${PROJECT_NAME}-${CONTEXT}
ports:
- ${JUPYTER_PORT}:8888
volumes:
- ./:/analysis
# data dir
- ${DATA_DIR}:/analysis/data
# コンテナ再作成後も notebook の設定が残るように設定を保存するディレクトリを共有する
- ${PWD}/.jupyter/nbconfig:/home/penguin/.jupyter/nbconfig
environment:
# workingdir に python の path を通すことで
# プロジェクトルートに配置した自作のモジュールを import できるようにしている
- PYTHONPATH=/analysis
working_dir: /analysis
env_file:
- .env
これを継承する形で記述することが多いでしょうか
# docker-compose.yml
version: '2.3'
services:
jupyter:
extends:
file: docker-compose.common.yml
service: jupyter
プロジェクトごとの拡張
以上で共有のライブラリに関してはバージョン管理できるようになりました。 次に個々のプロジェクトごとに何かしらのパッケージなりを追加したい場合についてですが同じように共通部分のイメージを使って行きます。具体的には以下のように From で gitlab registry を指定してやればOKです。
例えば静的サイトジェネレーターの nikola を追加で使いたくなったとしましょう。その場合一瞬だけ root になって pip install して最後もとの root のないユーザー (今回ならば penguin) に戻ればセキュリティもOKです。
# @./docker/Dockerfile FROM registry.gitlab.com/nyker510/analysis-template/cpu:latest WORKDIR /home/penguin # 一瞬だけ root 権限にする USER root RUN pip install nikola # あとで root 権限のないユーザーに戻す USER penguin
あとはこれを docker-compsoe.yml の Dockerfile に指定して
# @docker-compose.yml
version: '2.3'
services:
notebook:
build:
context: .
dockerfile: ./docker/Dockerfile
image: nyk-nikola-img
container_name: nyk-notebooks
volumes:
- ./:/book
- ${DATA_DIR}:/book/data
working_dir: /book
tty: true
command: jupyter notebook --ip 0.0.0.0 --port 8888
ports:
- ${JUPYTER_PORT}:8888
- 6005:8000
env_file: .env
docker-compose build しましょう。
04:28:49 in notebooks on master [!?] on 🐳 v18.06.1
➜ docker-compose build
Building notebook
Step 1/5 : FROM registry.gitlab.com/nyker510/analysis-template/cpu:latest
---> ee7f2c568e3c
Step 2/5 : WORKDIR /home/penguin
---> Running in 689b5ab30164
Removing intermediate container 689b5ab30164
---> 70e7f7df0880
Step 3/5 : USER root
---> Running in 9992f3324bf1
Removing intermediate container 9992f3324bf1
---> 501180a5296a
Step 4/5 : RUN pip install nikola
---> Running in b2bf143038ba
Collecting nikola
Downloading https://files.pythonhosted.org/packages/f3/b1/8dd93e9123eca1b0c3daef20bd9a424532f77d24ee7477ef74e099dacbba/Nikola-8.0.2-py3-none-any.whl (1.5MB)
Collecting Markdown<3.0.0,>=2.4.0 (from nikola)
Downloading https://files.pythonhosted.org/packages/6d/7d/488b90f470b96531a3f5788cf12a93332f543dbab13c423a5e7ce96a0493/Markdown-2.6.11-py2.py3-none-any.whl (78kB)
Requirement already satisfied: python-dateutil>=2.6.0 in /opt/conda/lib/python3.7/site-packages (from nikola) (2.8.0)
Collecting logbook>=1.3.0 (from nikola)
Downloading https://files.pythonhosted.org/packages/f6/83/20fc0270614919cb799f76e32cf143a54c58ce2fa45c19fd38ac2e4f9977/Logbook-1.4.3.tar.gz (85kB)
Requirement already satisfied: requests>=2.2.0 in /opt/conda/lib/python3.7/site-packages (from nikola) (2.21.0)
Requirement already satisfied: lxml>=3.3.5 in /opt/conda/lib/python3.7/site-packages (from nikola) (4.3.3)
Collecting natsort>=3.5.2 (from nikola)
Downloading https://files.pythonhosted.org/packages/e7/13/a66bfa0ebf00e17778ca0319d081be686a33384d1f612fc8e0fc542ac5d8/natsort-6.0.0-py2.py3-none-any.whl
Collecting unidecode>=0.04.16 (from nikola)
Downloading https://files.pythonhosted.org/packages/d0/42/d9edfed04228bacea2d824904cae367ee9efd05e6cce7ceaaedd0b0ad964/Unidecode-1.1.1-py2.py3-none-any.whl (238kB)
Collecting blinker>=1.3 (from nikola)
Downloading https://files.pythonhosted.org/packages/1b/51/e2a9f3b757eb802f61dc1f2b09c8c99f6eb01cf06416c0671253536517b6/blinker-1.4.tar.gz (111kB)
Requirement already satisfied: docutils>=0.13 in /opt/conda/lib/python3.7/site-packages (from nikola) (0.14)
Requirement already satisfied: mako>=1.0.0 in /opt/conda/lib/python3.7/site-packages (from nikola) (1.0.10)
Collecting PyRSS2Gen>=1.1 (from nikola)
Downloading https://files.pythonhosted.org/packages/6d/01/fd610d5fc86f7dbdbefc4baa8f7fe15a2e5484244c41dcf363ca7e89f60c/PyRSS2Gen-1.1.tar.gz
Collecting Pillow>=2.4.0 (from nikola)
Downloading https://files.pythonhosted.org/packages/a4/da/2bd281c875686230eabc13d20ab590ea617563b0e746abfb0698c4d5b645/Pillow-6.1.0-cp37-cp37m-manylinux1_x86_64.whl (2.1MB)
Collecting Babel>=2.6.0 (from nikola)
Downloading https://files.pythonhosted.org/packages/2c/60/f2af68eb046c5de5b1fe6dd4743bf42c074f7141fe7b2737d3061533b093/Babel-2.7.0-py2.py3-none-any.whl (8.4MB)
Requirement already satisfied: Pygments>=1.6 in /opt/conda/lib/python3.7/site-packages (from nikola) (2.4.0)
Collecting piexif>=1.0.3 (from nikola)
Downloading https://files.pythonhosted.org/packages/2c/d8/6f63147dd73373d051c5eb049ecd841207f898f50a5a1d4378594178f6cf/piexif-1.1.3-py2.py3-none-any.whl
Collecting Yapsy>=1.11.223 (from nikola)
Downloading https://files.pythonhosted.org/packages/f1/4c/c771fbc77045a45678cdd78f57fd4006259767c363c1f884071debd200f7/Yapsy-1.12.2.tar.gz (83kB)
Requirement already satisfied: setuptools>=24.2.0 in /opt/conda/lib/python3.7/site-packages (from nikola) (40.6.3)
Collecting doit>=0.30.1 (from nikola)
Downloading https://files.pythonhosted.org/packages/d0/4d/ebc39fdf33cc9e039b7c69f6783e929d184e5c0652a1a4543c6c5bd94c1c/doit-0.31.1-py3-none-any.whl (80kB)
Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.7/site-packages (from python-dateutil>=2.6.0->nikola) (1.12.0)
Requirement already satisfied: urllib3<1.25,>=1.21.1 in /opt/conda/lib/python3.7/site-packages (from requests>=2.2.0->nikola) (1.24.1)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.7/site-packages (from requests>=2.2.0->nikola) (2019.3.9)
Requirement already satisfied: idna<2.9,>=2.5 in /opt/conda/lib/python3.7/site-packages (from requests>=2.2.0->nikola) (2.8)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /opt/conda/lib/python3.7/site-packages (from requests>=2.2.0->nikola) (3.0.4)
Requirement already satisfied: MarkupSafe>=0.9.2 in /opt/conda/lib/python3.7/site-packages (from mako>=1.0.0->nikola) (1.1.1)
Requirement already satisfied: pytz>=2015.7 in /opt/conda/lib/python3.7/site-packages (from Babel>=2.6.0->nikola) (2019.1)
Collecting pyinotify; sys_platform == "linux" (from doit>=0.30.1->nikola)
Downloading https://files.pythonhosted.org/packages/e3/c0/fd5b18dde17c1249658521f69598f3252f11d9d7a980c5be8619970646e1/pyinotify-0.9.6.tar.gz (60kB)
Collecting cloudpickle (from doit>=0.30.1->nikola)
Downloading https://files.pythonhosted.org/packages/09/f4/4a080c349c1680a2086196fcf0286a65931708156f39568ed7051e42ff6a/cloudpickle-1.2.1-py2.py3-none-any.whl
Building wheels for collected packages: logbook, blinker, PyRSS2Gen, Yapsy, pyinotify
Building wheel for logbook (setup.py): started
Building wheel for logbook (setup.py): finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/a2/9f/6f/8c7a4ed6b9f6f3c98b742dbb0fd41fff3c130119c507376301
Building wheel for blinker (setup.py): started
Building wheel for blinker (setup.py): finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/92/a0/00/8690a57883956a301d91cf4ec999cc0b258b01e3f548f86e89
Building wheel for PyRSS2Gen (setup.py): started
Building wheel for PyRSS2Gen (setup.py): finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/08/2e/3d/50052096754e548b10de94a42182f27a1b18966dfa36c6b968
Building wheel for Yapsy (setup.py): started
Building wheel for Yapsy (setup.py): finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/2a/2f/b1/e60d7dd26d40e3bdfc219cf75ae806298989f33992a0d32c9a
Building wheel for pyinotify (setup.py): started
Building wheel for pyinotify (setup.py): finished with status 'done'
Stored in directory: /root/.cache/pip/wheels/e0/62/fe/a68c26dff6ed01a86d8a5aa8e01d7687a5a29c7d765af383cb
Successfully built logbook blinker PyRSS2Gen Yapsy pyinotify
Installing collected packages: Markdown, logbook, natsort, unidecode, blinker, PyRSS2Gen, Pillow, Babel, piexif, Yapsy, pyinotify, cloudpickle, doit, nikola
Successfully installed Babel-2.7.0 Markdown-2.6.11 Pillow-6.1.0 PyRSS2Gen-1.1 Yapsy-1.12.2 blinker-1.4 cloudpickle-1.2.1 doit-0.31.1 logbook-1.4.3 natsort-6.0.0 nikola-8.0.2 piexif-1.1.3 pyinotify-0.9.6 unidecode-1.1.1
WARNING: You are using pip version 19.1.1, however version 19.2.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Removing intermediate container b2bf143038ba
---> d4d891f28f54
Step 5/5 : USER penguin
---> Running in 0a7f94f5cb21
Removing intermediate container 0a7f94f5cb21
---> bc3957f6a589
Successfully built bc3957f6a589
Successfully tagged nyk-nikola-img:latest
04:33:09 in notebooks on master [!?] on 🐳 v18.06.1
➜ docker-compose up -d
Creating network "notebooks_default" with the default driver
Creating nyk-notebooks ... done
04:33:15 in notebooks on master [!?] on 🐳 v18.06.1 took 3s
➜ docker-compose ps
Name Command State Ports
-------------------------------------------------------------------------------------------------------
nyk-notebooks /usr/bin/tini -- jupyter n ... Up 0.0.0.0:6005->8000/tcp, 0.0.0.0:4001->8888/tcp
今回は単純にライブラリひとつだけでしたが root 権限になれるのでなんでもインストールできますから、無限に拡張は可能です。(もしかすると特殊なことをする場合共通部分のコードがじゃまするかもしれませんがその時はそもそも共通の Image を使わないという判断が適切なのかなと思います)
課題
めっちゃよさ気に書きましたが、この構成の課題もあります。
Image のテストはない
これはクリティカルな問題です。簡単にやるならばインストールしたライブラリが import できてあるクラスなり関数が呼び出せることを確認する、とかが考えられます。実際 CPU の Image はそれで OK だろうなと思っていて、まだ実装が出来ない(さぼってる)だけです。
しかしそれでも gpu の Image は実行環境に GPU がないとそもそも Image を gpu が使える状態で run 出来ないので Gitlab CI 上ではテストが出来ないので困ったなあという状況です。案がほしい…
回線が細いとしんどい
自分で build をしない分, docker pull することになるため回線が細いとひじょーに辛いことになります。僕は東京に出張にいくことがありリモートで作業することがありますが、家で事前に pull するのを忘れて出かけると pull が無限に終わらなくてかなり辛いです。
このあたりは Image を multi に切り分けるとかでキャッシュを上手く使えるように設計したほうがいいんでしょうが、まあ動くしなあというのでサボっています。
まとめ
Gitlab CI / Registry を使うことで自分の使いたいライブラリ郡をバージョンを管理しながら運用する方法を紹介しました。
とはいえ自分はインフラの専門家ではないですし、もっとこうすれば便利だよ!とか沢山あると思います。 その時はお手数ですが、一言お声がけいただけると大変うれしいです。;)
良き分析ライフを。
Kaggle Tokyo Meetup #6 の感想
はじめに
この記事は nyker_goto 的な視点で kagge meetup の内容について思ったことなどをまとめた記事です。
内容の詳細に関してはえじさんが https://amalog.hateblo.jp/entry/kaggle-tokyo-meetup-6 にて素敵な記事(網羅性がすごすぎる)にとてもきれいにまとめていただいているので、細かい内容について参照したい方はそちらを参考にしていただければと思います。
正直おもしろことだらけだったのですが、個人的に特に面白かった事柄は以下のようなことです。
- やることはきっちりやりましょう
- adam 一強
- CNNによる stacking
- ordered boosting
- チームの多様性大事
それぞれ順に書いていきます。
やることはきっちりやりましょう
今回発表を聞いていて一番思ったことです。発表いただいた上位入賞の皆さん本当にやることをきっちりとやっている印象でした。例えば…
- いろいろな方法やパラメータを試して、良かったものを採用する。思いつくやつは全部やる。
- 時間がかかっても有効とわかっているならば、やる。(plasticc のテンプレートマッチングなど最たるものだと思います)
- データ数/画像サイズが増えたときに objective がどう変わるかちゃんと見る。
- モデルが何を大事と思っているかを可視化して傾向を理解する。
- 過去のコンペの似たタスクで有効だったものを取り入れる。などなど。
どれもいうだけはとってもあたりまえのことです。 しかしそれを実際にやるのはなかなか難しいことで、それゆえにキッチリできたチームが上位に入っているのだと思います。
これは多分 Kaggle とかデータ分析とか関係なく、どんな問題に対しても同じ構造だと思います。 僕はわりと場当たり的にやってしまうことが多いので「やることをきっちりとやる」は肝に銘じたいと思います。
強い人は強い理由を淡々とやっていて、それは研究でもビジネスでもなんでも一緒な気がしている。
— ニューヨーカーGOTO (@nyker_goto) July 13, 2019
adam 一強
最適化大好き人間としてはこれは外せません。もはやずっと adam 固定でやって問題ないと思うようになりました。
今回の発表では俵さんの資料以外で adam 以外の optimizer は出てこなかったと思います。ことに phalanx さんによると「optimizer は adam で固定して本質で勝負する」とのことで若干衝撃をうけました。
というのも table data のように構造化されていて勾配が安定するタスクでは adam が強くて、画像のようなある種の多様体構造を学習する場合には sgd + nesterov + momentum でのんびり学習するほうが有効なのかなとぼんやりとイメージしていたからです。
論文ベースですが adam にはある種の弱点が指摘されていて、それを打ち消すように SGD とのいいとこ取りをした adabound なども提案されています. (自分のスライドですが https://speakerdeck.com/nyk510/que-lu-de-gou-pei-fa-falsehanasi?slide=17 この辺の話です。)
しかし phalanx さんが今までのタスクを解く際に adabound など adam 以外の optimizer を試していないわけがありません 。その経験から言って optimizer は本質ではないとなったというのはとてもおもしろいと思っています。
発表や個人的な経験としても、最適化手法よりも lr の調整方法 (cosine anealing などなど) のほうが効いてくることが多いですし、Quora Insincere Questions 10th Place Solution & 昔話 (tksさん) でも、重みの指数加重平均を使って予測する方法などが有効だったとのことでした。(optimizer のお話には触れられていなかったように思います)
これはすなわち optimizer の更新則自体をどう選ぶかより、それをどのように運用するかの方に関心が移っているしそれはそちらのほうが本質であるから、ということだと思います。
限られた時間と計算リソースを有効に使うためにも optimzier="adam" で固定して他に時間を使うべき、という意見は至極まっとうですしここでも「きっちりしているな」と思いました。
とはいえ最適化手法自体は好きなので今後も watch はしていきます👀
CNN による Stacking
phalanx さんの資料の二段目のモデルで採用されていた構造です。簡単に言うと $n$ 個のモデルが出力した $k$ クラス出力値を縦方向に重ねて、それに対して CNN で畳み込みをかけます。 これによってモデル同士の相関を捉えることができる、とのことでこれはいろんなタスクに使えそうで面白そうだなと思っています。モデルとしても全結合みたいにすべてのモデルの出力を使わない制約を加えて、モデル同士の関係性を学習させているというのはとても理にかなっているように思えました。
若干気になったのは phalanx さんはこの入力のモデルの順番は適当に入れ替えて学習しているということです。
順番が入れ替わって入力に入ってくるとき、CNN は何を学習しているんだろうか?(特定の順序に依存するような学習をしないとするならば何が学習されるのか)ちょっと直感的な理解ができておらず、誰か分かる人がいらっしゃたら教えていただきたい…
Ordered Boosting
端的にいうと「データが少ないときに catboost の ordered boosting は強いよ」ということです。これは nomi さんの https://speakerdeck.com/nyanp/plasticc-3rd-place-solution?slide=57 あたりを見ていただいたほうが早いので割愛します。素晴らしくわかりやすい。
チームの多様性大事
手法とかは関係ないですが kaggle でチームを作るときにはメンバー全員が個性を持っていてチーム全体で見たときに多様性がある方が強い、ということです。 wodori のチームも、nomi さんのチームもそうですが、メンバーひとりひとりが自立して特徴量、モデルの作成を行っていて、それ故にモデルの多様性も素晴らしく結果良い性能を出せたのかなと思っています。
反対に、誰かが特徴量作成を担当して、別の誰かはモデル作成だけ、みたいな組み方をするとどうしてもお互いに話ができない(特徴量のことはモデルの人はあまりわからないし逆もそう)ので、お互いが持っている多様な意見が交換できませんし、出来上がる予測も多様性がなく結果うまく行かないように感じています(ちなみに僕もこのモデル作成だけの人になったことがありとても反省しています)。
また自立してモデルを作るというのは、ひとりひとりがちゃんとソロでもいいとこに行くモデルを作る、ということに責任を持つことでもあると思います。 このようなコンセンサスが取れた状態でチームが組めれば、ある種のフリーライダーのようなことにもなりにくいですし、自分の責任範囲が明確になりますからモチベーションにもつながるように思います。 このような構造は決して kaggle のチームに限らず仕事でのプロジェクトでもなんでも同じだと思うので、非常によい学びでした。
まとめ
上記以外にも様々な面白いトピックがあり非常に楽しい Meetup でした。Kaggle をやっている人が一同に集まって議論ができるというのは素晴らしいことですね。自分も参加できたことがとても光栄です。
最後なりますが会場の準備をしていただいた DeNA の運営の方々、素晴らしい発表をしていただいた発表者の方々、楽しいお話をしていただいた参加者の方々、本当に有難うございました。
Atma杯#1 に参加予定の方は次回は大阪でお会いできるのを楽しみにしてます!
反省点
- 名前を本名で書いていたが誰もわからないので
"nyker_goto"で書いておけばよかった。 - もはやアイコンのTシャツで行くぐらいの勢いがほしい
- いつもののりで名刺をお渡ししていたけれど正直 twitter でつながりがある方ばかりなのでその時間お話すればよかった
- 知らない会場に行くのにはもっと時間の余裕を持って行くべき
- 髪の毛はもっと緑にするべき
Appendix
渋谷はいろいろと変わっていて全然わからない街になっていました。時の流れは早い。(写真はパルコの工事現場の写真です)
