Gpy vs scikit-learn: pythonでガウス過程回帰
Gpy と Scikit-learn
Python でガウス過程を行うモジュールには大きく分けて2つが存在します。 一つは Gpy (Gaussian Process の専門ライブラリ) で、もう一つは Scikit-learn 内部の Gaussian Process です。
- GPy: GitHub - SheffieldML/GPy: Gaussian processes framework in python
- Scikit-Learn 1.7. Gaussian Processes — scikit-learn 0.24.1 documentation
この2つのモジュールでどのような違いがあるのかを以下の項目で比較していきます。
- カーネルの種類, 可視化
- どんな種類のカーネルがあるのか
- 可視化は容易か
- 予測モデルの作成
- モデルの作成はどのように行うのか
- モデルの訓練方法, 結果の可視化方法はどうなっているか
- 事後分布からのサンプリング
- モデルの事後分布からのサンプリングを行えるか
使用した jupyter-notebook は以下の gist を参照してください。
GPy と Scikit-learn のガウス過程の比較 · GitHub
カーネルの種類, 可視化
カーネルを定義して可視化する難易度を比較していきます。
scikit-learn
scikit-learn でガウス過程をする際には sklearn.gaussian_process を用います。
カーネルの定義も同じ名前空間内に定義されていますので from sklearn.gaussian_process import kernels でインポートできます。
今回は Gpy のカーネルもインポートしていたので as を指定していますが別にそのままでも問題ないです。
色々とカーネルは定義されています (公式サイトを参照してください)
が今回は中心から遠くなると小さい値になる RBF カーネルと ExpSineSquared カーネル ( Periodic Kernel と呼ぶのが普通のような気がしますが sklearn ではこう呼ばれているようです) をかけ合わせたものを可視化します.
from sklearn.gaussian_process import kernels as sk_kern kern = sk_kern.RBF(length_scale=.5) kern = sk_kern.ExpSineSquared() * sk_kern.RBF() # ほかにも色々と種類はある。ドキュメント参照 # kern = sk_kern.RationalQuadratic(length_scale=.5) # kern = sk_kern.ConstantKernel() # kern = sk_kern.WhiteKernel(noise_level=3.) # 可視化は定義されていないので自分で用意する必要あり X = np.linspace(-2, 2, 100) plt.plot(X, kern(X.reshape(-1, 1), np.array([[0.]])))

GPyの場合
kern = GPy.kern.PeriodicExponential(lengthscale=.1, variance=3) * GPy.kern.Matern32(1) # kern = GPy.kern.RatQuad(1, lengthscale=.5, variance=.3) # kern = GPy.kern.White(input_dim=1) kern.plot()

kern = GPy.kern.Linear(input_dim=2) * GPy.kern.Matern52(input_dim=2) kern.plot()

違い
カーネルの数
GPy の方が用意されている関数の数が多いです。
具体的には PeriodicExponential など周期性を持ったカーネルや Matern52 のようなカーネルも用意されています。
可視化
GPy には可視化用の関数 plot が用意されています。
しかし Scikit-learn には同様のメソッドが無いため、自分で入力するベクトルを作る部分から書き下す必要があります。
定義方法
GPy においては、カーネルの定義の時点で、入力する特徴量の次元数 input_dim を指定する必要があります。
カーネル計算のためのデータがあたえられれば、特徴量の次元数は自明に判明するため、この変数はやや冗長のようにも感じられます。
一方 Scikit-learn ではカーネルの定義では純粋にカーネルの情報のみを入力すればよいです。
予測モデルの作成
Scikit-learn と GPy のそれぞれで、人工データに対する予測モデルを作っていきます。
データ作成
今回予測モデルに与える訓練データデータを作成します。 正しい関数は $f(x) = x + \sin(5x) $ とし, 分散 .1 のガウス分布によるノイズを付与します。
def true_func(x): """ 正しい関数 :param np.array x: :return: 関数値 y :rtype: np.array """ y = x + np.sin(5 * x) return y np.random.seed(1) x_train = np.random.normal(0, 1., 20) y_train = true_func(x_train) + np.random.normal(loc=0, scale=.1, size=x_train.shape) xx = np.linspace(-3, 3, 200) plt.scatter(x_train, y_train, label="Data") plt.plot(xx, true_func(xx), "--", color="C0", label="True Function") plt.legend() plt.title("トレーニングデータ") plt.savefig("training_data.png", dpi=150)
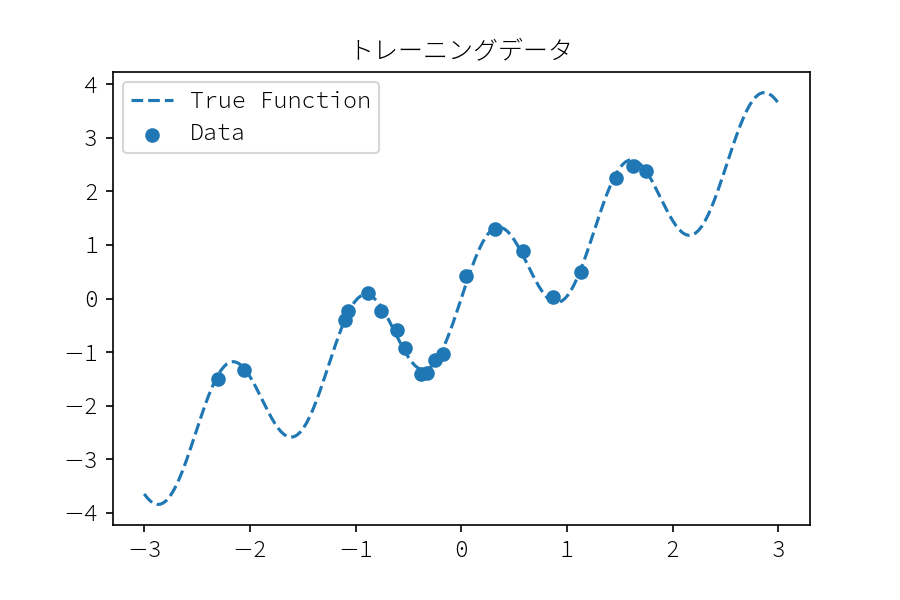
Scikit-learn
まず Scikit-learn でモデルを作成します。
kernel = sk_kern.RBF(1.0, (1e-3, 1e3)) + sk_kern.ConstantKernel(1.0, (1e-3, 1e3)) + sk_kern.WhiteKernel() clf = GaussianProcessRegressor( kernel=kernel, alpha=1e-10, optimizer="fmin_l_bfgs_b", n_restarts_optimizer=20, normalize_y=True)
パラメータ詳細
- alpha:
- normalize_y: default True
- 予測変数の平均を 0 になるように正規化します。Gaussian Process の計算の際の数値的安定性担保のため行われます.
- n_restarts_optimizer
- カーネルのハイパーパラメータを最適化する回数です。 0の場合1回の最適化で終わりますが、0以上が設定されると, 直前の最適化で得られた最適解を初期点として再び最適化を行います.
# X は (n_samples, n_features) の shape に変形する必要がある clf.fit(x_train.reshape(-1, 1), y_train) # パラメータ学習後のカーネルは self.kernel_ に保存される clf.kernel_ # < RBF(length_scale=0.374) + 0.0316**2 + WhiteKernel(noise_level=0.00785) # 予測は平均値と、オプションで 分散、共分散 を得ることが出来る pred_mean, pred_std= clf.predict(x_test, return_std=True)
def plot_result(x_test, mean, std): plt.plot(x_test[:, 0], mean, color="C0", label="predict mean") plt.fill_between(x_test[:, 0], mean + std, mean - std, color="C0", alpha=.3,label= "1 sigma confidence") plt.plot(x_train, y_train, "o",label= "training data") x_test = np.linspace(-3., 3., 200).reshape(-1, 1) plot_result(x_test, pred_mean, pred_std) plt.title("Scikit-learn による予測") plt.legend() plt.savefig("sklern_predict.png", dpi=150)
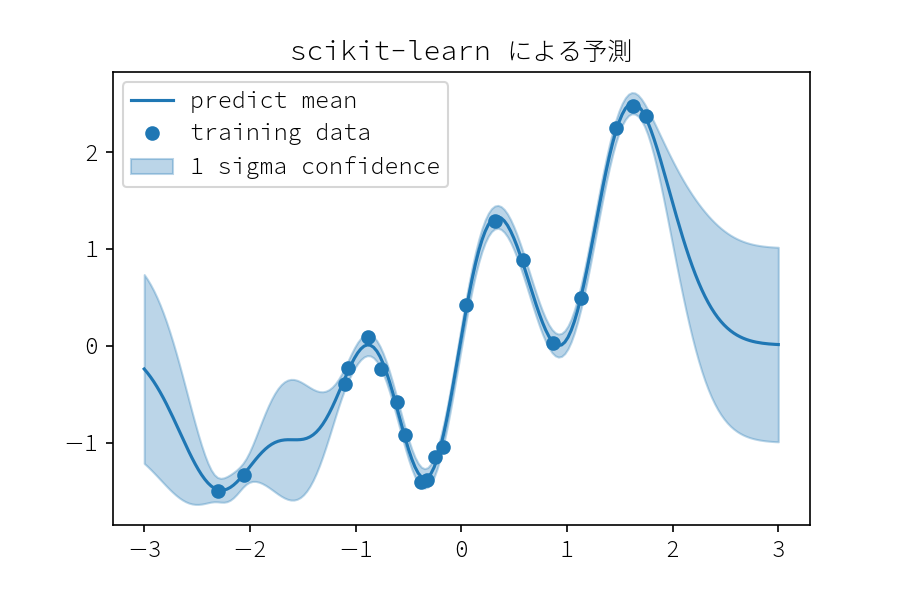
GPy
次に GPy で予測モデルを作成していきます.
import GPy.kern as gp_kern # kern = gp_kern.PeriodicMatern32(input_dim=1) * gp_kern.RBF(input_dim=1) kern = gp_kern.RBF(input_dim=1) + gp_kern.Bias(input_dim=1) kern = gp_kern.PeriodicExponential(input_dim=1) gpy_model = GPy.models.GPRegression(X=x_train.reshape(-1, 1), Y=y_train.reshape(-1, 1), kernel=kern, normalizer=None)
パラメータ詳細
- normalizer (default False)
- 予測変数
Yの正規化を決定する変数です。Noneが与えられるとガウス正規化が行われます。
- 予測変数
- noise_var (default 1)
fig = plt.figure(figsize=(6,8)) ax1 = fig.add_subplot(211) gpy_model.plot(ax=ax1) # 最適化前の予測 gpy_model.optimize() ax2 = fig.add_subplot(212, sharex=ax1) gpy_model.plot(ax=ax2) # カーネル最適化後の予測 ax1.set_ylim(ax2.set_ylim(-4, 4)) ax1.set_title("GPy effect of kernel optimization") ax1.set_ylabel("Before") ax2.set_ylabel("After") fig.tight_layout() fig.savefig("GPy_kernel_optimization.png", dpi=150)
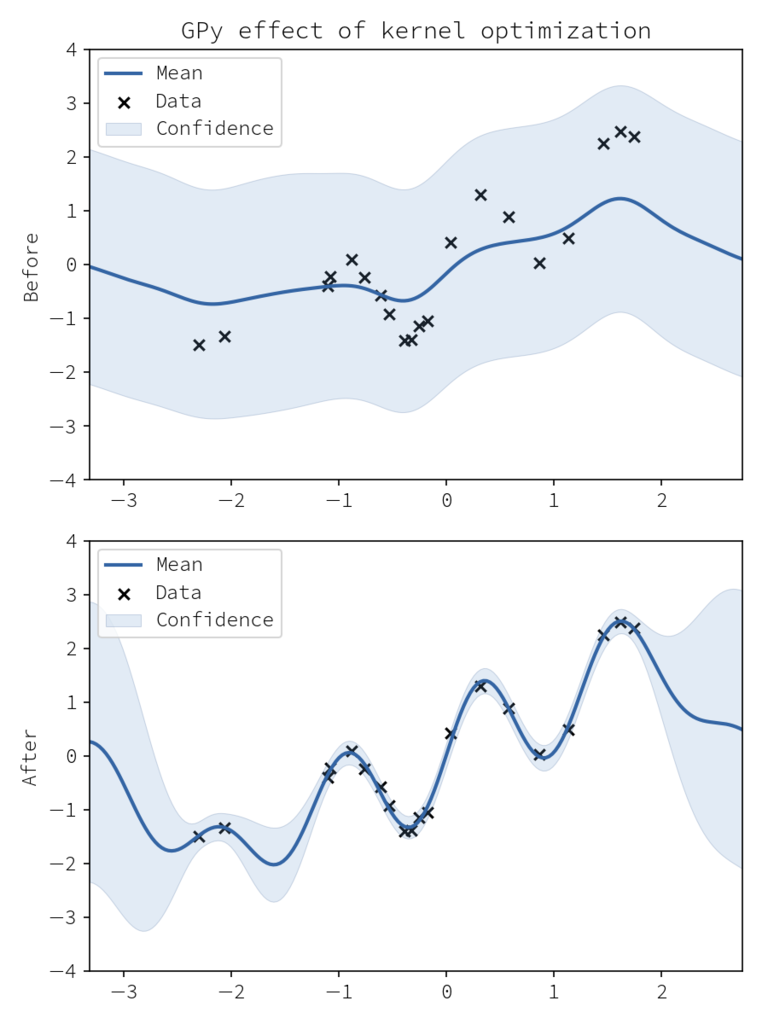
# 最適化されたモデルの確認 print(gpy_model)
Name : GP regression
Objective : 6.799282795295307
Number of Parameters : 4
Number of Optimization Parameters : 4
Updates : True
Parameters:
[1mGP_regression. [0;0m | value | constraints | priors
[1mperiodic_exponential.variance [0;0m | 2.85057672019 | +ve |
[1mperiodic_exponential.lengthscale[0;0m | 0.416248308257 | +ve |
[1mperiodic_exponential.period [0;0m | 11.478988407 | +ve |
[1mGaussian_noise.variance [0;0m | 0.00923971637791 | +ve |
pred_mean, pred_var = gpy_model.predict(x_test.reshape(-1, 1), ) pred_std = pred_var ** .5 plot_result(x_test, mean=pred_mean[:, 0], std=pred_std[:, 0]) plt.legend() plt.title("GPyによる予測") plt.savefig("GPy_predict.png", dpi=150)
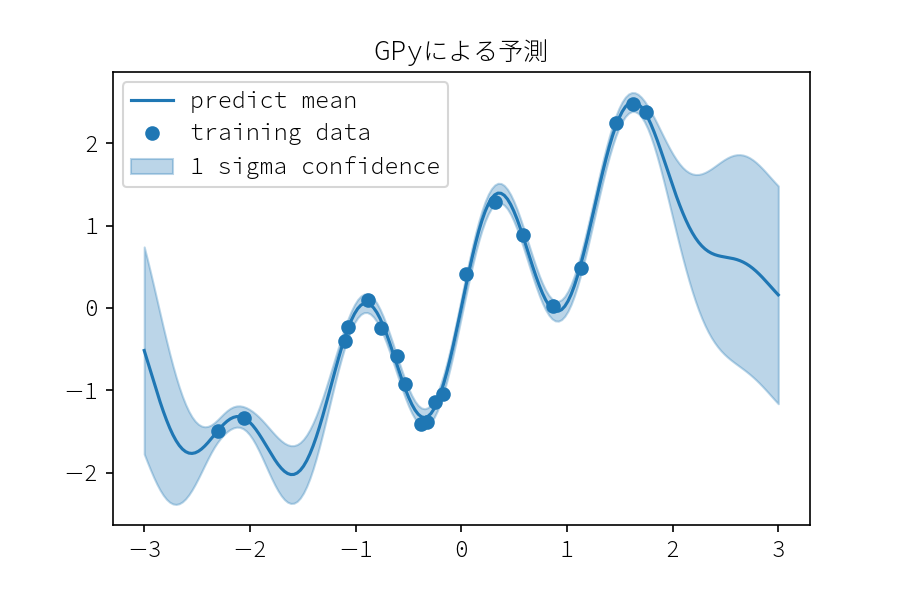
事後分布からのサンプリング
scikit-learn には、そもそもサンプリングする関数が存在しません。 (事後分布の共分散を取得して, 自分でゴニョゴニョ計算してサンプリングする必要があります. )
一方 GPy では posterior_samples という関数が用意されており, これを用いて事後分布からのサンプリングを行うことができます.
また posterior_samples_f を用いれば, 事後分布から確率過程をサンプルすることも可能です。以下では30個の確率過程をサンプリングして図示しています.
posterior = gpy_model.posterior_samples_f(x_test.reshape(-1, 1), size=30) for i, pos in enumerate(posterior.T): label = None if i == 0: label = "posteror" plt.plot(x_test[:, 0], pos, color="C0", alpha=.1, label=label) plt.plot(x_train, y_train, "o") plt.title("事後分布からのサンプリング") plt.legend() plt.savefig("posterior.png", dpi=150)

以上をまとめましょう。
カーネルの定義, 可視化
カーネルの種類
GPy の方が多くのカーネルが用意されていますので、GPy > Scikit-learn といえるでしょう。 しかし一方で生成時にデータの情報を入れ無くてはならないという冗長性があり、この点ではインスタンス生成時に純粋にカーネルに関する情報だけ入れれば良い Scikit-learn は綺麗です 🍺。
可視化
GPy >> Scikit-learn といえるでしょう.
GPy にはカーネル関数はもちろんのこと、予測モデル自体にもplotする機能がついています。
このため 「今回のデータにはどういう周期性を持ったカーネルが良いか」 などの検討を用意に行えます。
また model.optimize を呼び出す前後での model.plot をすることで、最適化の妥当性のチェックをすぐさま行うことができます。
予測モデルの作成
事後分布平均と分散
事後分布の平均値と分散の取得はどちらのライブラリでも簡単に取得することができます。この点で違いは無いです。
手続き的な違い
GPyではインスタンス生成時にデータ X, y をわたし, model.optimize メソッドの呼び出し時に、カーネルのパラメータを最適化します。
一方で, Scikit-learn ではインスタンス生成時には何も行わずインスタンス変数の初期化のみを行い, fit メソッドでデータ X, y をわたし, ここで同時にカーネルのパラメータ最適化を行っています。
事後分布からのサンプリング
Scikit-learn では一つの点での平均と分散を得ることはできますが、事後分布から確率過程をサンプリングすることはできません。
一方で GPy では poseterior_samples, poseterior_samples_f を用いればかんたんに事後分布からのサンプルを行えます.
その他の違い
GPyにはシンプルなガウス過程を用いた回帰問題以外にも, 損失関数をポアソン分布に変更し、二次の意味でガウス分布として近似してやるポアソン回帰モデルなども作成することができ, 拡張性に長けています。*1
一方 Scikit-learn では 回帰と分類 のモデルのみで, 複雑な目的関数を扱う枠組みは用意されていません。
以上のことから
- GPy
- Scikit-learn
という使い分けをするのがよいと言えるでしょう。
scikit-learn 準拠の予測モデルのつくりかた
機械学習で色々やっていると、いろいろなモデルを複合したアンサンブルモデルなど、自分で新しい予測モデルを作りたい場合があります。
その場合自分でいちから作り上げても良いのですが、そうやって作ったモデルは、たとえば scikit-learn のパラメータ最適化モジュールである GridSearch や RandomSearch を利用することができなくて、少々不便です。
この際に scikit-learn の定義にしたがってモデルを定義すればうまく連携がとれて効率的です。以下では scikit-learn 準拠の予測モデルをどうやって作ればよいか、その際の注意点や推奨事項を取り上げます。
- 参考
- Creating your own estimator in scikit-learn http://danielhnyk.cz/creating-your-own-estimator-scikit-learn/
Scikit Learnの予測モデル
はじめに、作成するモデルのタイプを選びます。scikit-learn ではモデルは以下の4つのタイプに分類されています。
Classifer- ex). Naive Bayes Classifer などの分類モデル
Clusterring- ex). K-mearns 等のクラスタリングモデル
Regressor- ex). Lasso, Ridge などの回帰モデル
Transformer- ex). PCA などの変数の変換モデル
それぞれのモデルに対して Mixin が定義されていて, BaseEstimator と同時にそれも継承することが推奨されています。
BaseEstimator, 各Mixinのコードは以下を参照してください https://github.com/scikit-learn/scikit-learn/blob/14031f6/sklearn/base.py
予測モデルのコンストラクタでの制約
予測モデルのコンストラクタには以下の制約が存在します。
__init__で呼ばれるすべての引数は初期値を持たなくてはいけません。- 入力変数の確認は
__init__内部では行いません。fitが呼ばれたときに行うようにします。 __init__でのすべての引数は作成されたインスタンスの属性と同じ名前を持つことが推奨されます。(たとえば引数hogeをself.huga = hogeのように与えることはだめです。)__init__ではデータを与えません。fitメソッドで初めて与えるようにします。
Fit method
fit メソッド内ではデータの加工及びパラメータの確認を行います。
この部分以外でデータを取り扱うのは非推奨です(繰り返しになりますが、例えば __init__内部でデータをあたえてnormalizeする等です)。
get_params & set_params
get_params と set_params は BaseEstimator によって定義されている関数です。これをオーバーライドするのは推奨されません。
予測値の取扱
返すベクトルをインプットしなくても良い場合が存在します。(例えばクラスタリングのときなどです)。その場合でも、実装上の問題から、予測値yを引数に定義することが必要です。( y=None で定義することが推奨されます)。こうすることで GridSearch に予測器を与えることが可能になります。
score と gridsearch
グリッドサーチにかけるためには、必要であれば score メソッドをオーバーライドする必要があります。 なぜならばグリッドサーチでは「どのモデルが最も良いのか」を判断する必要があり、その基準となる score メソッドが必要だからです。
score メソッドは 数字が大きいほど良いモデル というルールがあります。 したがって最小化問題が目的関数となっているモデルでは、それにマイナスをつけたものを score として登録する必要があります。 (LassoやRidge回帰のような, 二乗ロス関数を損失関数に持つモデルを gridsearch にかけると、モデルのスコアが負になって表示されるのはこのためです。) 後述する Mixin クラスには score メソッドがすでに定義されているので, Mixin クラスのデフォルトの score メソッドを用いる場合には自分で定義する必要はありません。
サンプル
以上を踏まえた予測器を定義していきます。今回は [訓練データの平均値 + int_val] よりも大きいか小さいかをboolで返す分類器を作成します。分類器なので BaseEstimator と同時に ClassiferMixin も継承しています。
# coding: utf-8 __author__ = "nyk510" from sklearn.base import BaseEstimator, ClassifierMixin from sklearn.model_selection import RandomizedSearchCV import numpy as np class SampleClassifer(BaseEstimator, ClassifierMixin): """ 分類器のサンプル """ def __init__(self, int_val=0, sigma=.5, hogevalue=None): """ 分類器のコンストラクタ 全部の引数に初期値を与えること !! :param int int_val: :param float sigma: :param str hogevalue: """ self.int_val = int_val self.sigma = sigma self.hogevalue = hogevalue self.huga = hogevalue # 引数とインスタンス変数の名前が違っている. 非推奨. def fit(self, X, y=None): """ データへのフィッティングを行うメソッド。 すべての加工, パラメータの確認はここで定義する。 Note: `assert`よりも`try/exception`を用いるほうが本当は良い. けどめんどうなのでassert使ってます :param numpy.ndarray X: 2-D array. 訓練特徴 :param numpy.ndarray y: 1-D array. ターゲット変数 :return: self :rtype: SampleClassifer """ assert(isinstance(self.int_val, int) or isinstance(self.int_val, np.int64)), "int_valは整数値でないと駄目です. " self.treshold_ = (sum(X)/len(X)) + self.int_val return self # return selfするのが慣習 def _meaning(self, x): """ 平均値よりも大きければTrueを返す分類 :rtype: bool """ if x > self.treshold_: return True else: return False def predict(self, X, y=None): """ 予測を行う :param numpy.ndarray X: 特徴量. 2-D array :param numpy.ndarray y: ターゲット変数. 分類問題なので使わないけど`y=None`でおいておく :return: 1-D array :rtype: np.ndarray """ try: getattr(self, "treshold_") except AttributeError: raise RuntimeError("モデルは訓練されていません") return ([self._meaning(x) for x in X]) def score(self, X, y=None): """ モデルの良さを数値化する なんでもいいけれど、大きい方が良くて、小さいほうがだめ。 今回は平均以上の値がいくつあるかをスコアとして定義する。 :return: 平均値の値よりも大きい数 :rtype: int """ return (sum(self.predict(X)))
ところでこの ClassiferMixin にある Mixin とは何でしょうか。wikipediaを引用すると
mixin とはオブジェクト指向プログラミング言語において、サブクラスによって継承されることにより機能を提供し、単体で動作することを意図しないクラスである。 Mixin - Wikipedia
Mixin は継承することで初めて機能を提供できるクラスを指しています。Scikit-Learnの ClassiferMixin のコードを見ると以下が定義されています。
class ClassifierMixin(object): """Mixin class for all classifiers in scikit-learn.""" _estimator_type = "classifier" def score(self, X, y, sample_weight=None): """Returns the mean accuracy on the given test data and labels. In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted. Parameters ---------- X : array-like, shape = (n_samples, n_features) Test samples. y : array-like, shape = (n_samples) or (n_samples, n_outputs) True labels for X. sample_weight : array-like, shape = [n_samples], optional Sample weights. Returns ------- score : float Mean accuracy of self.predict(X) wrt. y. """ from .metrics import accuracy_score return accuracy_score(y, self.predict(X), sample_weight=sample_weight)
自分の名前(_estimator_type)とscore関数のデフォルトが定義されています。
score関数内ではインスタンスメソッドのself.predict(X)が呼ばれているので、このクラスはBaseEstimatorを継承してpredictを持っているインスタンスに継承されて初めて意味があるものだとわかります。
python では __init__ メソッドを定義せずにインスタンスメソッドのみを定義することで、新しく Mixin クラスを作ることが可能です。
つぎに、適当にデータを作成してこのモデルに対してランダムサーチをしてみましょう。
x_train = np.random.normal(.1, 4, size=100) x_test = np.random.normal(-.1, 4, size=20) model_params = { "int_val": [-10, -1, 0, 1, 2], "sigma": np.linspace(-1, 1, 100) } clf = SampleClassifer() random_search = RandomizedSearchCV(estimator=clf, param_distributions=model_params) random_search.fit(x_train)
score関数はTrueの数が多いほど大きいという風に定義していますから、int_valが一番小さい値(すなわち-10)の予測器がbest_estimator_となっているはずです。
(本当はRandomSearchなので -10 が選択されているとは限らない, ということに今気が付きました……ほんとうはGridSearchすべきでしたね)1
random_search.best_params_
{'int_val': -10, 'sigma': 0.51515151515151536}
ちゃんと -10 が選ばれていることが分かります。
-
int_valのとりうる値の数は5なので, 1 - (4/5)**10 ~ 0.892 より, -10 が1回でも選ばれる確率はだいたい 89.2%です↩
matplotlibで高校生っぽいグラフを描く
高校の時によくみたグラフをmatplotlibで書いてみたくなったので、やってみました。
練習として初めてデコレーターを使って、プロットしたオブジェクトをいじって軸をあれこれするようにしてみました。
機能としてあるのは知っていたのですが、使ってみるとデコレーターって意外と便利ですね。やっぱり食わず嫌いは良くないなと思いました。
作れる画像はこんな感じです。


意外と苦労するのが軸の矢印を作るところで、画像の縦横比が変わった時にもちゃんと特定の比率の長方形に頂点を持つ矢印を持つようにしてあります。さっくり適当なグラフを書くのには使えるかも。
DCGANをChainerで実装
DCGANとは
DCGANはランダムなベクトルから画像を生成するGeneratorと、画像が与えられた時にその画像がGeneratorによって作られたものなのか、本当の画像なのかを判定する関数Discriminatorでなりたっています。
DCGANのアイディア
この2つの関数を相互に競わせるように更新することで、画像を生成するGeneratorをもっともらしいものへと更新します。
Generatorは、できるだけDiscriminatorに偽物だと判定されないように、重みを更新します。
反対に、Discriminatorは、できるだけGeneratorの画像を本物だと判定しないように、重みを更新します。
しくみとしてはこれだけで構成されていて、DCGANではGeneratorに逆Convolution(Deconvolution)を、DiscriminatorにConvolutionを用います。またConvolutionを行う際、BatchNormalizationを行うことで、高速な学習を可能にします。
実装する
今回はChainerを用いて、DCGANを実装しました。コードはgithubに置いています。https://github.com/Nyker510/hobby
僕のローカル環境ではGPUを使うことができないので、cpuを用いたコードになっていますので、そのまま使うととても遅いのでそれだけは注意してください。
構成としてはGenerator,Discriminatorを定義しているdcgan.pyとデータを与えて最適化していくtrainer.pyで構成されています。
dcgan.py
まずはGeneratorから
class Generator(Chain): '''ランダムなベクトルから画像を生成する画像作成機 ''' def __init__(self, z_dim): super(Generator, self).__init__( l1=L.Linear(z_dim, 3 * 3 * 512), dc1=L.Deconvolution2D(512, 256, 2, stride=2, pad=1,), dc2=L.Deconvolution2D(256, 128, 2, stride=2, pad=1,), dc3=L.Deconvolution2D(128, 64, 2, stride=2, pad=1,), dc4=L.Deconvolution2D(64, 1, 3, stride=3, pad=1), # Convolution, Deconvolutionともに値は画像の大きさに合わせて変化させる # 必要がある。 # 今回はMNISTをターゲットにするので、元の大きさは28×28 # 元の512チャンネルから1チャンネル(MNISTは白黒なためチャンネルが無い)に変換するまでに # 3→4→5→10→28となるようにstride,pad,windowの大きさを選んでいる # bn0 = L.BatchNormalization(6*6*512), bn1=L.BatchNormalization(512), bn2=L.BatchNormalization(256), bn3=L.BatchNormalization(128), bn4=L.BatchNormalization(64), ) self.z_dim = z_dim def __call__(self, z, test=False): h = self.l1(z) # 512チャンネルをもつ、3*3のベクトルに変換する h = F.reshape(h, (z.data.shape[0], 512, 3, 3)) h = F.relu(self.bn1(h, test=test)) h = F.relu(self.bn2(self.dc1(h), test=test)) h = F.relu(self.bn3(self.dc2(h), test=test)) h = F.relu(self.bn4(self.dc3(h), test=test)) x = self.dc4(h) return x
Generatorはランダムなz_dim次元ベクトルを受け取って画像として返す関数です。今回実験対称としてMNISTの白黒画像を用いることを想定しているので、最後画像として返すDeconvolution関数を(28,28)次元のチャンネル数1と鳴るように、stride,pad,windowの大きさを選んでいます。
なので、違う大きさの画像でやりたいという場合や、RGBのある画像(チャンネル数が3)でやりたいというときは、それに合わせて変化させる必要があります。
(例えばRGBでやりたいのであれば、 dc4=L.Deconvolution2D(64, 3, 3, stride=3, pad=1)です)
これと反対方向に、即ち画像を受け取って2値に写像する関数として、Discriminatorも定義します。
trainer.py
trainer.pyでは実際に最適化を行っていきます。
大切なところは、lossをどのように与えるか、の部分です。
z = np.random.uniform(-1, 1, (batchsize, self.z_dim)) z = z.astype(dtype=np.float32) z = Variable(z) x = self.gen(z) y1 = self.dis(x) # 答え合わせ # ジェネレーターとしては0と判別させたい(騙すことが目的) loss_gen = F.softmax_cross_entropy( y1, Variable(np.zeros(batchsize, dtype=np.int32))) # 判別機としては1(偽物)と判別したい loss_dis = F.softmax_cross_entropy( y1, Variable(np.ones(batchsize, dtype=np.int32))) # load true data form dataset idx = perm[i * batchsize:(i + 1) * batchsize] x_data = self.X[idx] x_data = Variable(x_data) y2 = self.dis(x_data) # 今度は正しい画像なので、0(正しい画像)と判別したい loss_dis += F.softmax_cross_entropy( y2, Variable(np.zeros(batchsize, dtype=np.int32)))
仮定として、Discriminatorの二次元の出力の内、0次元目を正しい画像である確率、1次元目を間違った画像(Generatorによって作成された偽画像)である確率であるとします。
まずzを適当なランダムベクトルとして設定した後、それをGeneratorに渡すことで画像xを作成します。その後、xをDiscriminatorに渡して二次元のベクトルy1を得ます。
Generatorとしては、Discriminatorを騙すことが目的です。
言い換えると、この画像xをDiscriminatorに渡した時に「本物だ!」と思わせたいのです。したがって全てのy1が0次元目の値が大きくなって欲しいので、ロスとしてy1と0とのSOFTMAXを与えます。
反対にDiscriminatorとしては、この画像xをちゃんと偽物であると判定しなくてはなりません。
すなわち1次元目が大きい値を取るようになって欲しいので、Discriminatorのロストしてはy1と1とのSOFTMAXを与えます。
そしてつぎに,Discriminatorに正しい画像も与えてあげて、これをちゃんと正しい画像(つまり0)と判定してほしいので、y2と0とのSOFTMAXをロスに加えます。
実験結果
MNISTの画像を使って実験を行います。本当は0~9でやれば一番良いのですが、GPUが使えない環境なので無限に時間がかかって終わりません。ですので泣く泣く、0の画像だけを用いて実験を行いました。
training中、epochが終わるごとにランダムなベクトルから画像をGeneratorによって作成してプロットさせていて、その画像を示します。同時にDiscriminatorが出力した「この画像が本物である確率」も画像の上に表示しています。
1 epoch目

ただのノイズです。
100 epoch目

だいぶ画像っぽくなってきました。がしかしDiscriminatorには正しい画像だとは思われていないようです。
500 epoch目

かなりしっかりと0を作るようになっています。正しい画像である確率が0.3程度になるなど、Discriminatorも判定に苦労している様子が伺えます。
1000 epoch目

500epoch目に比べて白黒の部分がはっきりとしてきました。
まとめ
今回はMNISTの0の画像だけというシンプルなタスクですが、学習が進むに連れて明確な輪郭をもって画像を出力する様子が確認できました。GPU環境であれば、更に高次の特徴をもった画像(例えばキャラクターのイラストなど)でも作成できるようなので、画像の自動生成技術として様々な用途で使えるかもしれません。